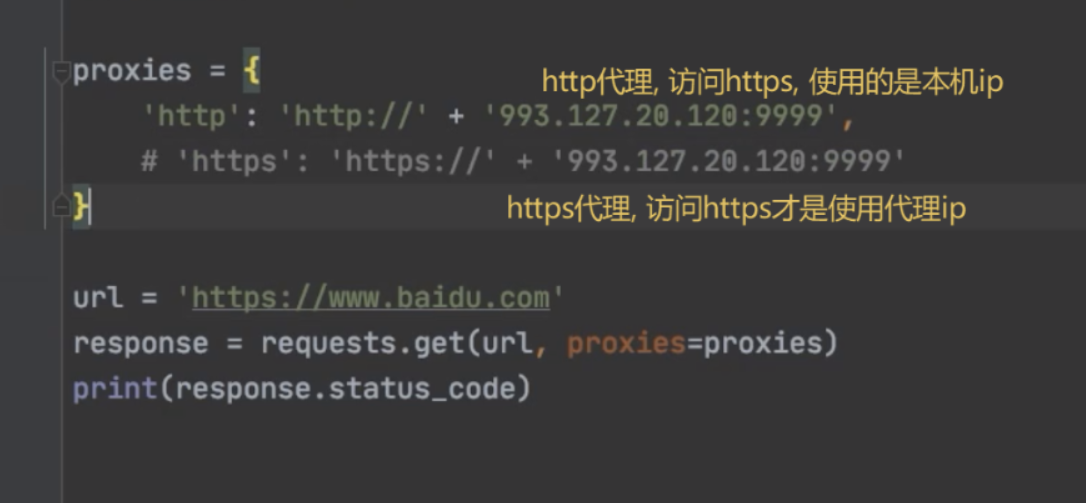
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
|
import random
import time
import requests
import re
import asyncio
import aiohttp
import aiomysql
import traceback
import retrying
from tenacity import retry, stop_after_attempt, retry_if_exception_type, retry_if_exception
from aiohttp import ClientResponse, TCPConnector
from feapder.network.user_agent import get
from lxml import etree
"""全局变量, '快代理'的基本代理参数配置 """
username = "d4472377283"
password = "rudm2ozb"
api_url = "https://dps.kdlapi.com/api/getdps/?secret_id=o5b3w54kddfiskjsu5ta&signature=tr45ga5grnvp1943h0paert5qwquy7cb&num=1&pt=1&format=json&sep=1"
class AmazonCommodityInfo:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36",
'cookie': 'i18n-prefs=USD; session-id=130-9348969-9472654; ubid-main=132-4278027-6860024; session-id-time=2082787201l; lc-main=zh_CN; sp-cdn="L5Z9:HK"; session-token=xqGp4dFymTVT+Qou8E0C2TbIAa0eDkCWp0kxfL0lbh0uk7OU/KqojGDABQOz5Cc8Q63u6IPfMIwKNxoE8hvyKjvGOaB5tXqgsfpxaYK9+A1uVYCHXZuOnuzP9WdkFzjHEJQixMf/bblxWCN0RjvdbGsxluPYrRnvzg53QIZyy/F5Y+xPf7FygYkJ4ah53K/Ema15wI2/IuEInrWUV8rOLwWuDgfqHbPoWdnyaxHc39WelWFBjYNL+cGsPcvyZUmfms6lZi+sLMCOQBzqY/THpkMHUWpucP13amAmRthipjAXbhmO+JJcSHASN06K6pH7hTrawP5P+bNYxKHVb27oPefWWsLBw/R8; skin=noskin; csm-hit=tb:s-6K5TXMJ99AG0F2BMDE5G|1737183719347&t:1737183720056&adb:adblk_yes',
"Referer": "https://www.amazon.com/s?i=specialty-aps&bbn=16225013011&language=zh",
"X-Requested-With": "XMLHttpRequest",
"downlink": "10",
"ect": "4g",
"rtt": "200",
}
"""链接"""
catalog_url = "https://www.amazon.com/nav/ajax/hamburgerMainContent?ajaxTemplate=hamburgerMainContent&pageType=Gateway&hmDataAjaxHint=1&navDeviceType=desktop&isSmile=0&isPrime=0&isBackup=false&hashCustomerAndSessionId=9265450a4a37ea1ecc6f3377d5c592346f0ab06a&languageCode=zh_CN&environmentVFI=AmazonNavigationCards/development@B6285729334-AL2_aarch64&secondLayerTreeName=prm_digital_music_hawkfire%2Bkindle%2Bandroid_appstore%2Belectronics_exports%2Bcomputers_exports%2Bsbd_alexa_smart_home%2Barts_and_crafts_exports%2Bautomotive_exports%2Bbaby_exports%2Bbeauty_and_personal_care_exports%2Bwomens_fashion_exports%2Bmens_fashion_exports%2Bgirls_fashion_exports%2Bboys_fashion_exports%2Bhealth_and_household_exports%2Bhome_and_kitchen_exports%2Bindustrial_and_scientific_exports%2Bluggage_exports%2Bmovies_and_television_exports%2Bpet_supplies_exports%2Bsoftware_exports%2Bsports_and_outdoors_exports%2Btools_home_improvement_exports%2Btoys_games_exports%2Bvideo_games_exports%2Bgiftcards%2Bamazon_live%2BAmazon_Global&customerCountryCode=HK"
aim_url = "https://www.amazon.com/s?i=specialty-aps&bbn={}&page={}&language=zh"
"""ip相关"""
proxy_auth = aiohttp.BasicAuth(username, password)
ip_queue = asyncio.Queue()
max_retries = 11
async def get_proxy_ip(self):
async with aiohttp.ClientSession(connector=TCPConnector(ssl=False)) as client:
async with client.get(api_url) as response:
if response.status == 200:
data = await response.json()
proxy_ip = "http://" + data.get('data').get('proxy_list')[0]
print(f"log: 从快代理获取到的ip为: {proxy_ip}")
await self.ip_queue.put(proxy_ip)
return proxy_ip
else:
print(f"请求失败,状态码: {response.status}")
return None
async def fetch(self, client, url, input_headers=None):
headers = self.headers if input_headers is None else input_headers
retries = 1
while retries < self.max_retries:
while True:
if self.ip_queue.empty():
await self.get_proxy_ip()
proxy_ip = await self.ip_queue.get()
test_ip_url = "http://httpbin.org/ip"
try:
async with client.get(test_ip_url, proxy=proxy_ip, proxy_auth=self.proxy_auth, timeout=2) as response:
if response.status == 200:
json_data = await response.json()
if 'origin' in json_data:
backtrack_ip = "http://" + json_data['origin']
print(f"proxy_ip {proxy_ip}, 访问转发backtrack_ip: {backtrack_ip}")
break
else:
print(f"log: 验证ip失败 {response.status}, ip不可用")
except Exception as e:
print(f"log: 验证ip报错: {e}")
try:
async with client.get(url, proxy=proxy_ip, proxy_auth=self.proxy_auth, headers=headers, timeout=5) as response:
if response.status == 200:
await self.ip_queue.put(proxy_ip)
print(f"log:请求{url}成功, 使用IP:{proxy_ip}")
content_type = response.content_type
match content_type:
case "application/json":
return await response.json()
case "text/html":
return await response.text()
case _:
return await response.text()
else:
print(f"log:重试次数: {retries}, 请求失败,状态码:{response.status}")
except Exception as e:
print(f"log:重试次数: {retries}, 报错 {e}")
retries += 1
await self.ip_queue.put(proxy_ip)
print(f"log:达到最大请求数量, {url}未请求成功")
"""需求实现"""
async def get_commodity_catalog(self, client) -> list:
json_res = await self.fetch(client, self.catalog_url)
if 'data' not in json_res:
print("错误: 响应中没有'data'字段")
return []
await asyncio.sleep(0.6)
catalog_id_list = re.findall("bbn=(\d*)", json_res['data'])
catalog_id_list = list(set(catalog_id_list))
print(f"log:所有商品id列表{len(catalog_id_list), catalog_id_list}")
return catalog_id_list
async def get_page_commodity(self, client, commodity_id):
input_headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.7',
'accept-encoding': 'gzip, deflate, br, zstd',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8',
'cache-control': 'no-cache',
'cookie': 'i18n-prefs=USD; session-id=130-9348969-9472654; ubid-main=132-4278027-6860024; session-id-time=2082787201l; lc-main=zh_CN; sp-cdn="L5Z9:HK"; skin=noskin; session-token=GKkaoAAhd7tMD+5bkg1Sp6oCfsjyKWaEkp4RHPqYi35vsc/OF/D0Ps6g+mxd2O1xmf+no/UHm5LwVwE3BvKt0CDVBw5rsXDp6QM6qRlnjwYJ1EIGqSFmAK92DnmG5urFfyTncC/Xc5oraOUngQowkQV45hGT+bxi7+0lDwekP7uFirhJsjbSIhmfYbHf92wgfZMRhrBxss3KTQvuSQ0qetliwyAkxkPhT8a5D9N2kd3PZQ0xc/uf5l6dD4t2hAUmMnxr0zzEYh4V6u/7Nor4n7nwegbSLseXJYd4MfIcd6cPyDa1sQNHv+Atey6/Gyu3157bRjPuvQE2yPuSennHpuPZ9Tt2BszT; csm-hit=tb:s-TF8PP3ZB5Z7AT54AQ0WN|1737186961126&t:1737186961536&adb:adblk_yes',
'device-memory': '8',
'downlink': '4.75',
'dpr': '1.125',
'ect': '4g',
'pragma': 'no-cache',
'priority': 'u=0, i',
'rtt': '250',
'sec-ch-device-memory': '8',
'sec-ch-dpr': '1.125',
'sec-ch-ua': '"Not A(Brand";v="8", "Chromium";v="132", "Google Chrome";v="132"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-ch-ua-platform-version': '"15.0.0"',
'sec-ch-viewport-width': '2274',
'sec-fetch-dest': 'document',
'sec-fetch-mode': 'navigate',
'sec-fetch-site': 'same-origin',
'sec-fetch-user': '?1',
'upgrade-insecure-requests': '1',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/132.0.0.0 Safari/537.36',
'viewport-width': '2274',
}
for page in range(100):
text = await self.fetch(client, self.aim_url.format(commodity_id, page), input_headers=input_headers)
html_obj = etree.HTML(text)
flag = html_obj.xpath('//h2[@class="a-size-medium-plus a-spacing-none a-color-base a-text-bold"]/text()')
if not flag:
break
group = html_obj.xpath('//div[@class="sg-col-20-of-24 s-result-item s-asin sg-col-0-of-12 sg-col-16-of-20 sg-col s-widget-spacing-small sg-col-12-of-16"][1]')
sava_tasks = list()
for good in group:
try:
title = good.xpath('.//h2[@class="a-size-medium a-spacing-none a-color-base a-text-normal"]/span/text()')[0]
price = good.xpath('.//span[@class="a-price"]//span[@class="a-offscreen"]/text()')[0]
url = "https://www.amazon.com/" + good.xpath('.//a[@class="a-link-normal s-no-hover s-underline-text s-underline-link-text s-link-style a-text-normal"]/@href')[0]
print(f"log:商品{title},{price}, {url}xpath解析成功")
except Exception as e:
print(f"log:xpath解析失败", e)
continue
coroutine_obj = self.sava_commodity(title, price, url)
sava_tasks.append(asyncio.create_task(coroutine_obj))
await asyncio.wait(sava_tasks)
@staticmethod
async def create_table():
async with aiomysql.connect(host="localhost", user="root", password="root", db="py_spider") as db:
async with db.cursor() as cursor:
sql = "SHOW TABLES LIKE 'tb_amazon';"
flag = await cursor.execute(sql)
if not flag:
sql = """
create table if not exists tb_amazon (
id int auto_increment not null primary key,
title varchar(255),
price varchar(255),
url varchar(255)
) engine = innodb;
"""
try:
await cursor.execute(sql)
print("log:tb_amazon建表成功")
except Exception as e:
print("error", e)
else:
print("log:tb_amazon表已存在")
@staticmethod
async def sava_commodity(title, price, url):
pool = await aiomysql.create_pool(host="localhost", user="root", password="root", db="py_spider")
async with pool.acquire() as connects:
async with connects.cursor() as cursors:
sql = "insert into tb_amazon(title, price, url) values(%s,%s,%s)"
try:
await cursors.execute(sql, (title, price, url))
await connects.commit()
print(f"log:商品数据{title},{price},{url}插入成功!")
except Exception as e:
print(f"log:商品数据{title},{price},{url}插入失败! ", e)
await connects.rollback()
async def launch(self):
async with aiohttp.ClientSession() as client:
commodity_list = await self.get_commodity_catalog(client)
await self.create_table()
tasks = list()
for commodity_id in commodity_list:
coroutine_obj = self.get_page_commodity(client, commodity_id)
tasks.append(asyncio.create_task(coroutine_obj))
results = await asyncio.gather(*tasks, return_exceptions=True)
if __name__ == '__main__':
amazon_commodity_info = AmazonCommodityInfo()
asyncio.run(amazon_commodity_info.launch())
|