
11.Scrapy框架

第一章 关于python虚拟环境
[[2.需要用到的python基础知识#十一. Python环境]]
第二章 Scrapy基本知识
Scrapy官方文档: https://docs.scrapy.org/en/latest/topics/commands.html (就看英文的, 中文看了能笑死人🤣)
Request和Response对象: https://docs.scrapy.org/en/latest/topics/request-response.html
第一节 理论知识
2.1.1 为什么学Scrapy框架
- 代码量比
reqeusts少70% - 支持异步(
Twisted异步网络框架)
2.1.2 异步和非阻塞
- & 说明: 阻塞是指需要等待请求结果而不能继续执行下面的语句(比如多线程中, 线程A遇到了网络请求需要等待, 虽然可以切到线程B继续执行, 但对于A来说, 还是阻塞的, 所以多线程是阻塞的; 而异步编程async, 是无需等待的, 直接可以运行下面的语句,等浏览器响应后, 会调用回调函数告知从而获取结果)


2.1.3 适合同步的爬虫工作流程
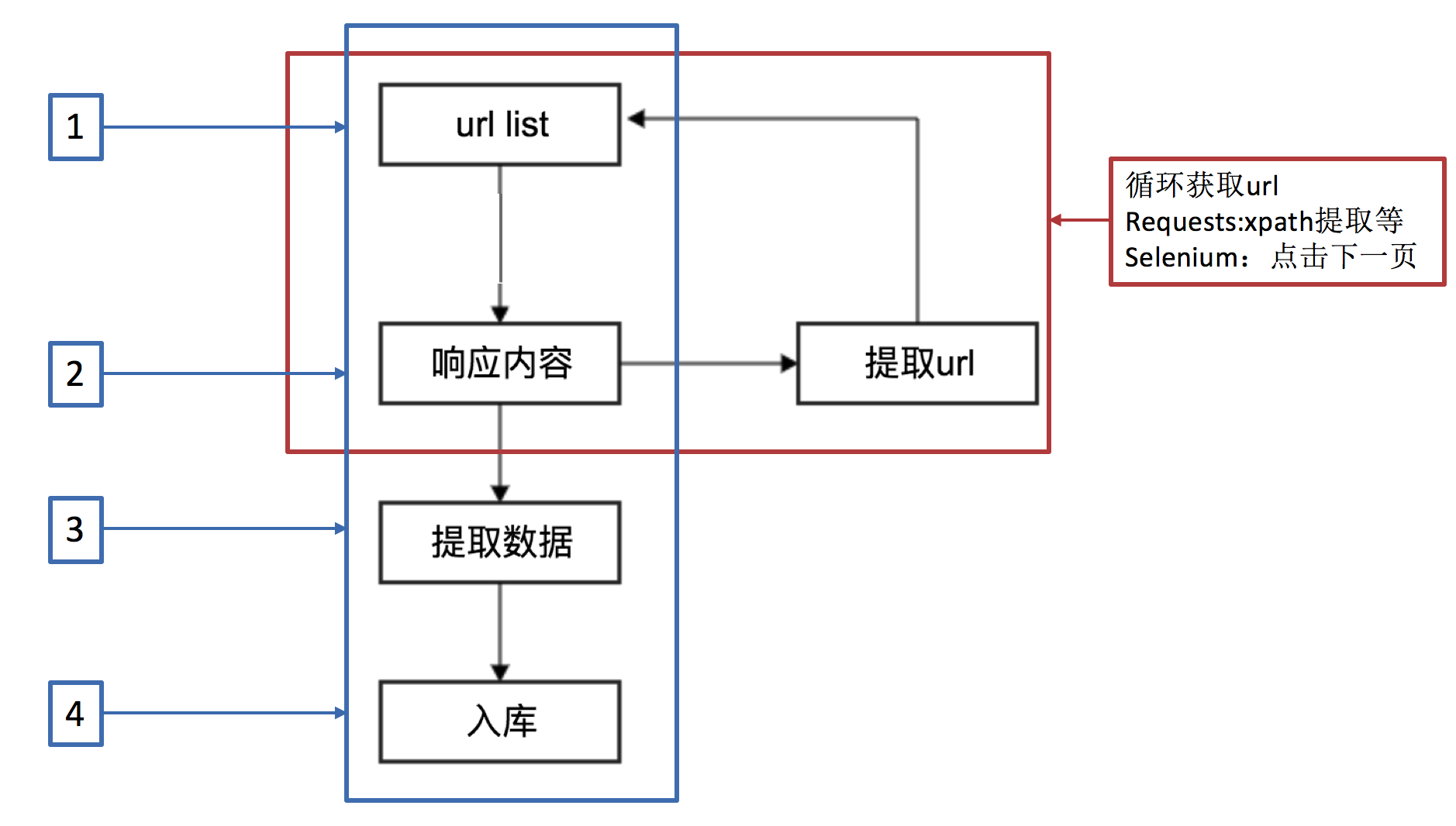
2.1.4 适合异步的爬虫工作流程
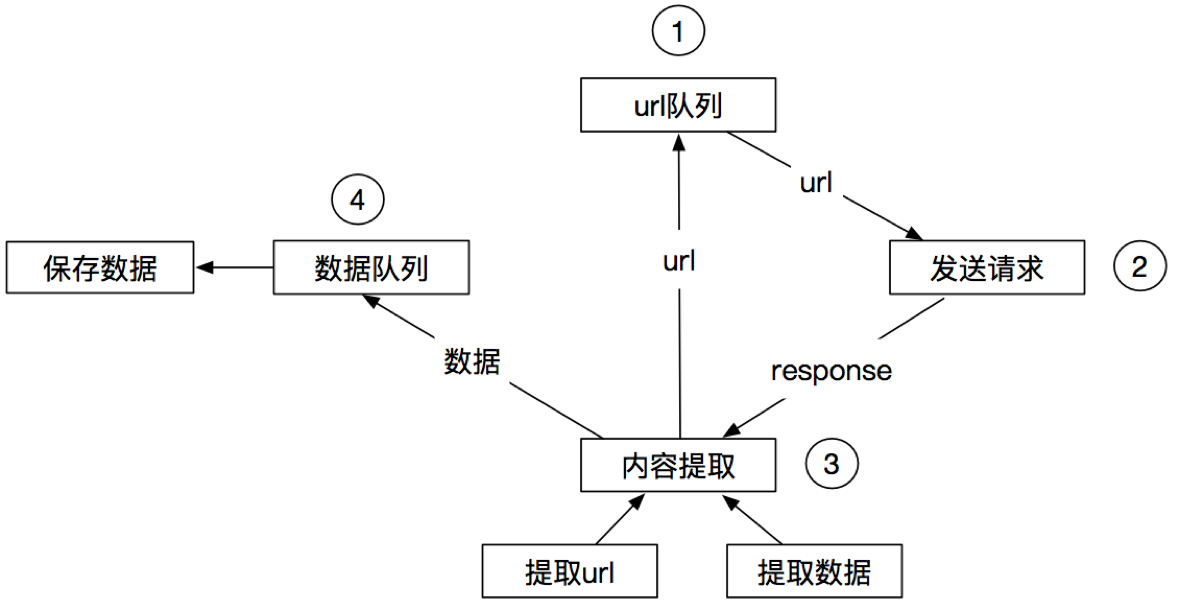
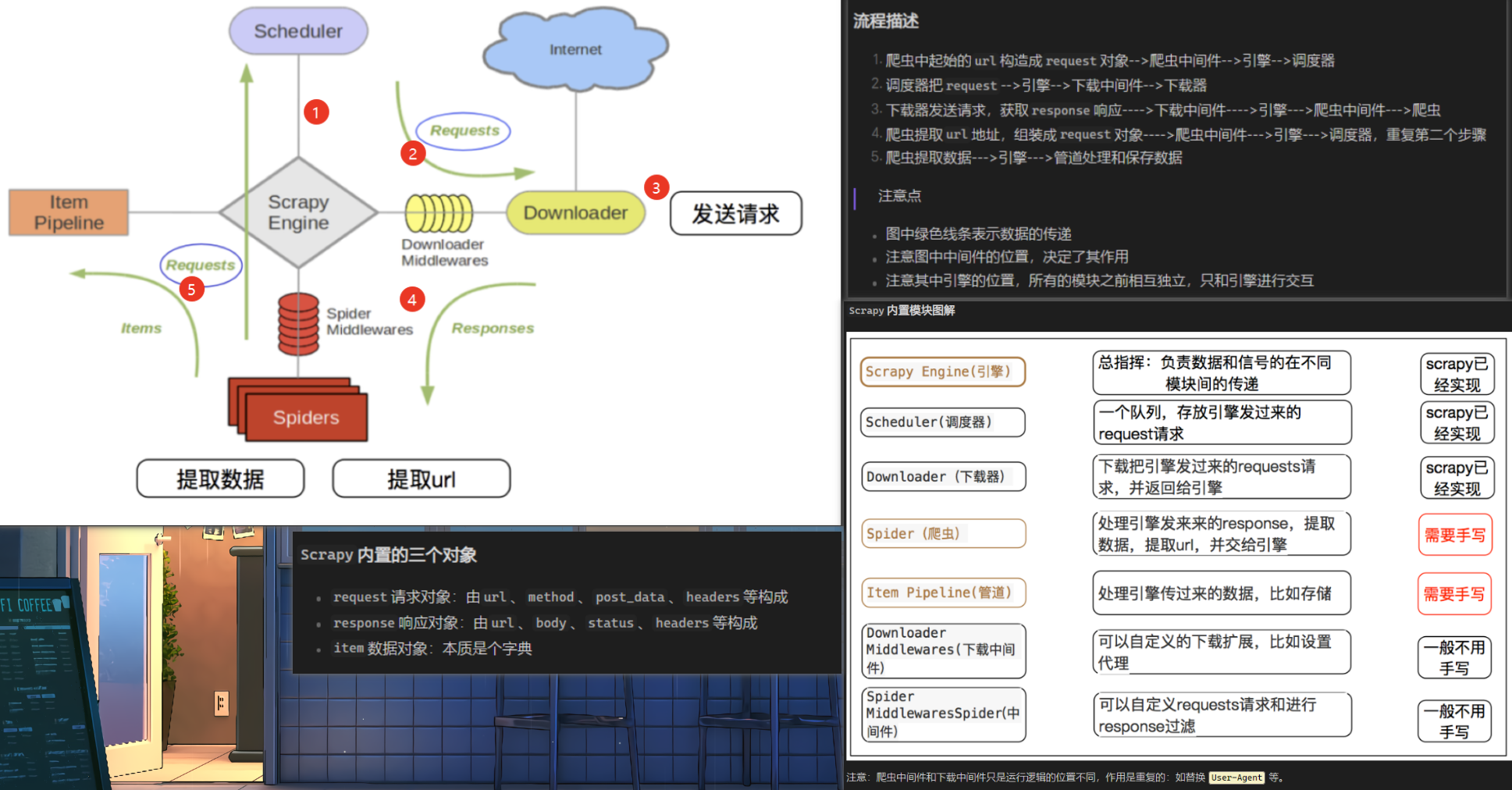
2.1.5 Scrapy框架的工作流程♒
微观图
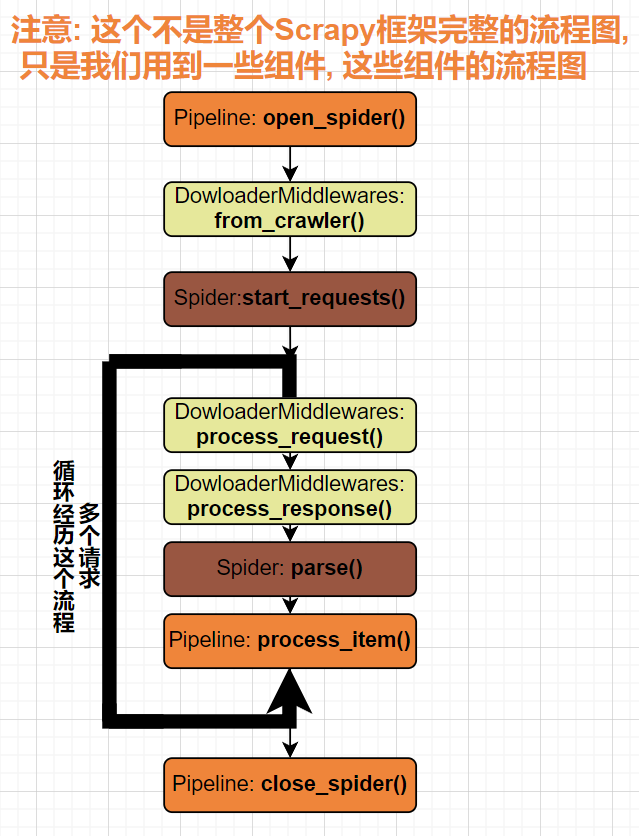
单个正常请求(200)
- Engine向Scheduler要url*(实际上是Request对象)*
- scheduler从请求队列中拿url, 并返回给Engine
- Engine经过下载中间件 到Downloader
- Downloader处理请求【如果请求这个正常200】
- 经过下载中间件返回给Engine
- 后续: Engine经过爬虫中间件给Spider, spider做后续处理
宏观图
第二节 Hello Scrapy
STEP1:下载scrapy
- & 说明: 直接
pip install scrapy
STEP2: 搭建scrapy框架
- $ 语法:
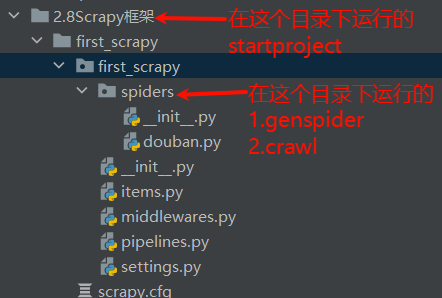
scrapy startproject 项目名称 - ! 注意: 该命令会①生成一个first_scrapy文件夹 ②在这个文件夹中还会生成first_scrapy的包 ③这个包下才是真正的目录结构 [[2.需要用到的python基础知识#十二. 文件夹和包的区别]]
1 | scrapy startporjcet first_scrapy |
STEP3: 创建爬虫文件
- $ 语法: cd到first_scrapy目录下运行
scrapy genspider 爬虫文件名 允许爬虫的域名
1 | scrapy genspider douban movie.douban.com/top250 |
STEP4: 运行
- $ 语法: cd到first_scrapy目录下运行
scrapy crawl douban
1 | scrapy crawl douban |
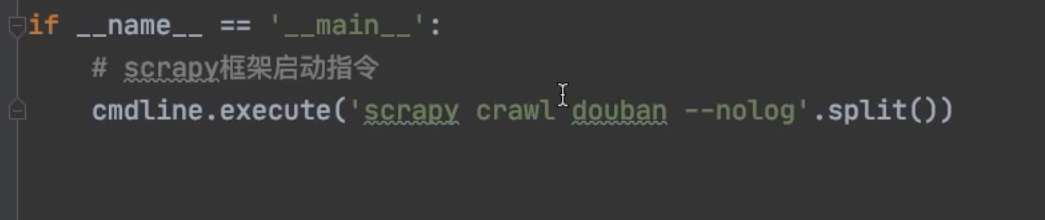
- $ 语法: 使用
scrapy.cmdline在生成的爬虫文件中直接运行(不通过cmd)
1 | if __name__ == '__main__': |
STEP5: [可选]日志处理
- & 说明: 可以看到, scrapy默认是打印了非常多日志信息的, 不想看的方法有以下两种(当然出错了还得要看的, 非常重要)
- 关闭日志[不建议]
- $ 语法:
scrapy crawl douban --nolog
- $ 语法:
- 控制台步显示日志, 将日志保存在一个文件中
- $ 语法: 进到setting中, 写这两行
- ! 日志等级: DEBUG<INFO<WARNING<ERROR<CRITICAL 这里设置为WARNING, 比WARNING低的日志信息都不会保存.
1 | # 日志保存并设置日志保存等级 |
第三节 文件目录解析
- & 说明: 一图流, 只是简单了解下, (后续肯定会更新这张图的)

第四节 response对比requests常用方法
| 序号 | requests模块常用方法 | 作用 | scrapy模块常用方法 | 返回值 | 作用 |
|---|---|---|---|---|---|
| ① | result.text | 返回以文本格式(HTML代码) | response.text | ||
| ② | result.content | 返回以二进制格式 | response.body | ||
| ③ | result.json() | 返回以json格式 | response.json() | ||
| ④ | result.status_code | 返回此次请求服务器返回的状态码 | response.status | ||
| ⑤ | result.headers | 获取响应头 | response.headers | ||
| ⑥ | result.request.headers | 获取该次请求的请求头 | request.headers | ||
| ⑦ | result.cookies | 获取cookies | request.headers | cookie在reqeustのheaders中看 | |
| ⑧ | result.content.decode("指定编码") | 先返回二进制, 然后自定义解码获取html源码 | response.body.decode("utf-8") | ||
| ⑨ | response.xpath("\\ol...") | <class ‘scrapy.selector.unified.SelectorList’> | 配合extract和extract_first使用,[[11.Scrapy框架#第五节 作业(爬取豆瓣电影信息)]] |
第五节 实战(请求头,Cookie)
需求: 爬取豆瓣电影信息
- & 说明: 上面那个Hello Scrapy [[11.Scrapy框架#第二节 Hello Scrapy]]是将项目搭建出来, 同时
douban.py, 是”处理引擎发来的response, 提取数据, 提取url,再交回给引擎”的作用, 我们写数据清洗就在这里写 - $ 语法: Scrapy底层是集成了lxml的, 所以支持xpath; 具体怎么用? 看代码!

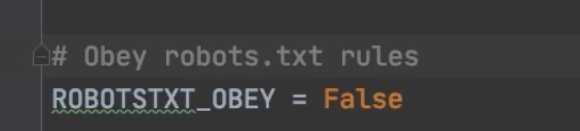
2.5.1 关闭”君子协议”
- $ 语法: 进到
settings.py中
2.5.2 设置请求头
- $ 语法: 进到
settings.py中,

2.5.3 设置Cookies
- ! 检查点: ①Cookies_Enable=False ②请求头中添加Cookies
- $ 语法: 进到
settings.py中, 设置两处(①是设置是否禁用Cookies, 选择False, 如果注释掉是不开其Cookie ②是在请求头中带上Cookie头)

2.5.4 全部代码
1 | import scrapy |
第六节 实战2(pipelines items 翻页)
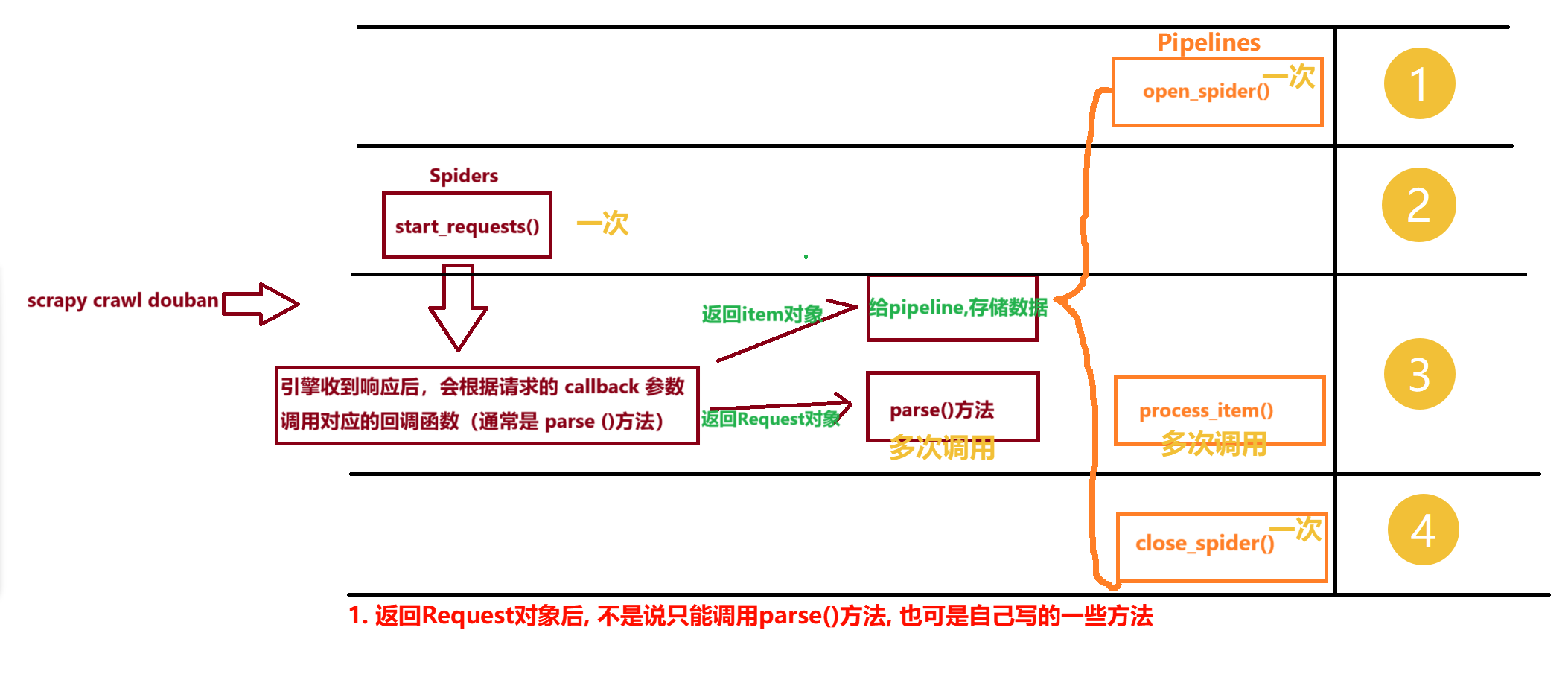
2.6.1 联动pipelines实现”数据存储”
- ! 检测点: ①setting是否配置 ②spiders是否传回的是字典 ③多个pipelines是否return item ④强转
dict() - & 说明: 看图,那两个一次的, 正好可以进行 数据库的连接和关闭
- ! 注意: open_spider(), process_item(), close_spider()只有在
piplines.py中才可以重写, 但可以有多个类, 不同的类可以不同的重写

- 存储到mysql数据库
1 | from itemadapter import ItemAdapter |
- 存储到mongodb数据库
- ! 注意: 这里需要将item转为字典, 否则报没id的异常
1 | class MongoSpiderPipeline: |
settings.py
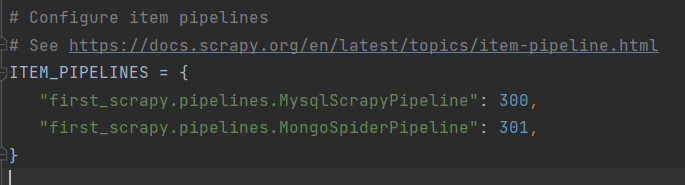
- ! 这里需要”激活”pipeline, 才能用, 这里的300, 301代表权重,数字越小, 越先得到item值, 第一个管道得到的值是从spiders来的, 如果上一个管道没有return item, 后面的管道就拿不到这个值 (后面的管道只能拿到上一个管道return的值) 【类似与责任链的设计模式】
2.6.2 联动items实现”数据定义”
- ! 检查点: ①items名称是否对的上 ②spiders中是否实例化的是items定义的类而不是普通的Dict( ) ③导包 set source packege
- & 说明: items的作用就是, 定义你要存储的格式(不定义类型)
- ! 注意:
scrapy.Item其本质上是一个字典(最高父类是字典)
- STEP1: 在items中”定义数据”
1 | # Define here the models for your scraped items |
- STEP2: 在parse中导入, 并实例化item作为字典返回, 不在返回Dict()
1 | import scrapy |
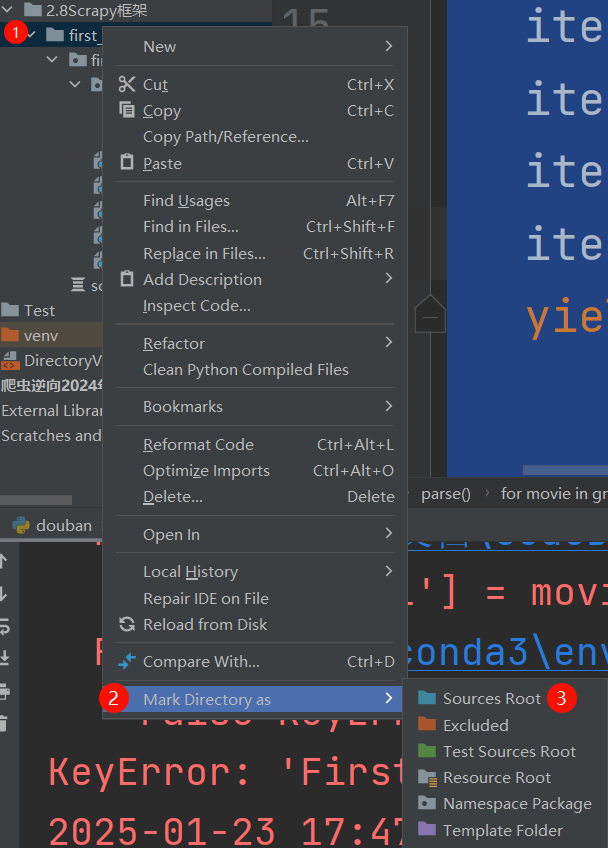
- STEP3: 将框架的文件夹设为”根文件夹”, 否则无法导入包【左图】
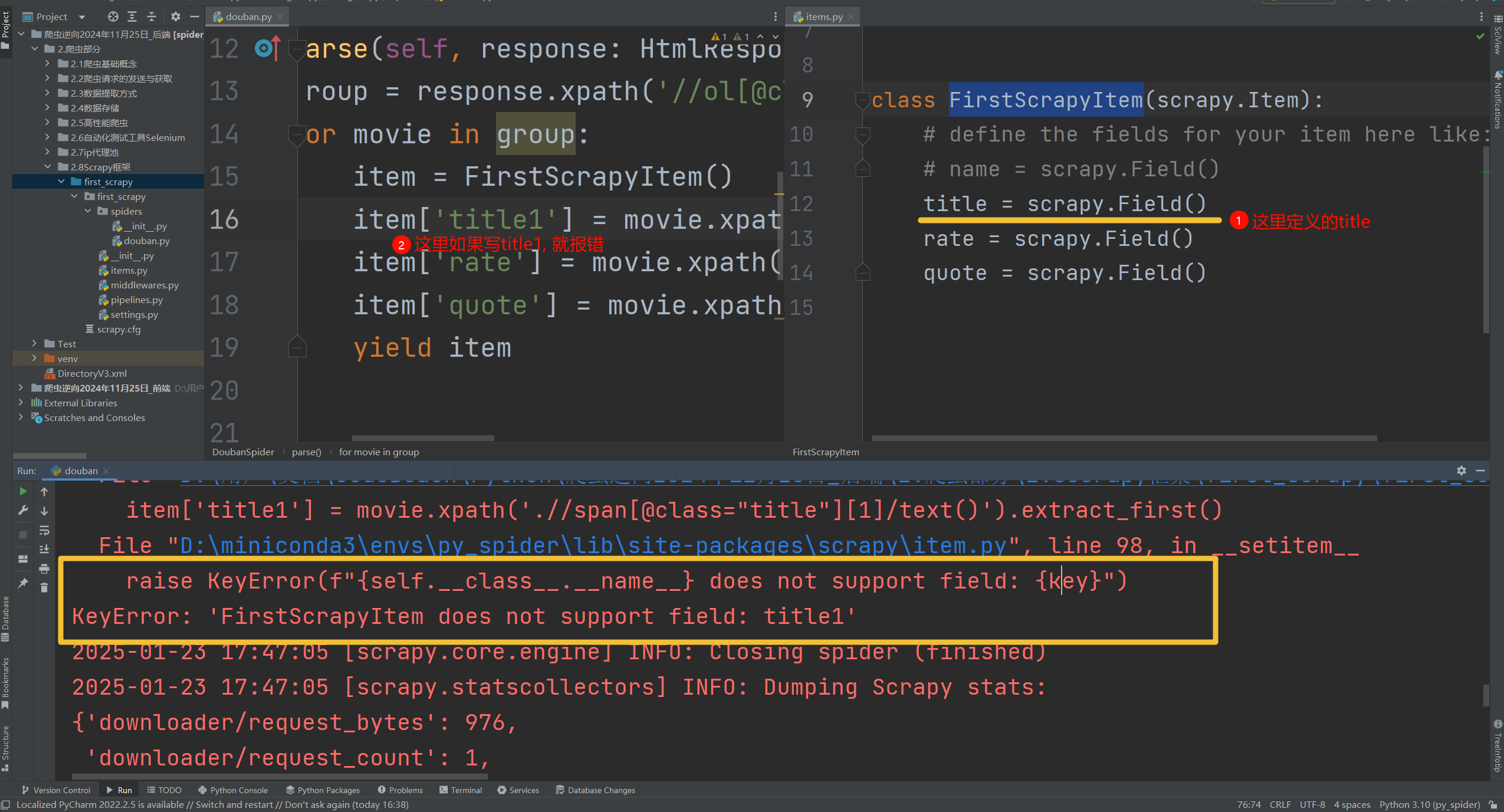
- ! 注意: 如果数据定义对不上, 会发生什么? 【右图】
2.6.3 实现翻页
- ! 检测点: ①重写start_requests( )方法, 请求我指定的url, 而不是默认的start_urls
- 思路一: 获取页面的”下一页”标签, 如果有href就表示还有下一页,否则就是翻页结束
1 | import scrapy |
- 【推荐】思路二: 重写
start_reqeusts()方法- & 说明: 当执行
scrapy crawl douban后, 会发生如下的事情【左图】请注意⚠️看start_requests()方法的默认编写【右图】, 所以我们如果把默认遍历start_url, 重写为遍历每一页, 不就可以实现每页数据的读取了. - ! 注意: start_requests()确实是整个周期只执行一次,但你要执行完! 程序运行到了parse, 是callback让他回调到那的, 不是说执行了parse, 就代表start_requests执行完了
- & 说明: 当执行

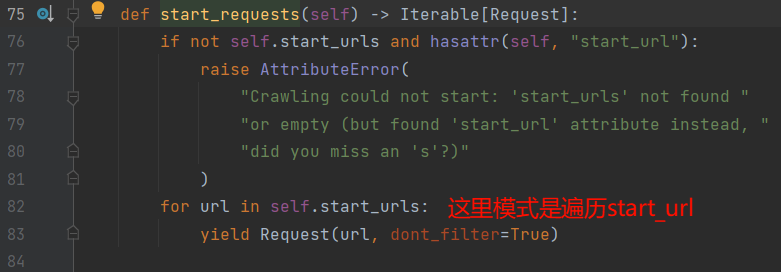
1 | import scrapy |
第七节 实战3(meta, URL去重, 发送POST请求)
2.7.1 meta
- ! 检查点: ①返回Request时携带meta字典【meta是个字典!!!】 ③response.meta获取这个字典
需求:我现在需要爬每个电影的详细页的数据
- & parse是处理全部页的请求的, 我现在需要处理电影详细页的请求, 我需要将item从
parse()方法–>parse_detail()方法,在detail处理好后再yield给pipeline,此时就要用到meta - $ 语法:①放入: 通过Request(meta=字典) ②取出: 通过response.meta[键]获取
- ! 注意: Spiders中的类可以自己写方法, 但一定要有self, response这两个形参
1 | import scrapy |
2.7.2 URL去重
- & 如果我们希望, 我们发送的url中存在相同url时, 只发送一个, 我们需要设置
dont_filter变量- $ case1: 当dont_filter设置为True时,Scrapy将不会对该请求进行去重检查,即使该请求的URL已经存在于调度器中。
- $ case2: 当dont_filter设置为False(默认值),Scrapy会检查请求的URL是否已经被调度过,如果是,则不会再次调度该请求。
- ! dont_filter是Request对象的属性, 下面yield的写法, 相当于
request.dont_filter=True
1 | def start_requests(self): |
2.7.3 发送POST请求 🕳️
- & 有两种发送POST请求的方法, 但是有区别
- $ 方式一:
Request(url, body=json.dumps(请求体字典), method="POST",callback: 这种方法请求时会用json(字符串)发过去- ! 注意⚠️: 如果想要&拼接的方式, 可以使用 urllib的方法
urlencode(字典), 让body=urlencode(data)就可以实现FormRequest的&方式
- ! 注意⚠️: 如果想要&拼接的方式, 可以使用 urllib的方法
1 | import json |
- $ 方式二:
FormRequest(url, formdata=字典, callback): 这种方法请求会用&拼接过去
1 | def start_requests(self): |
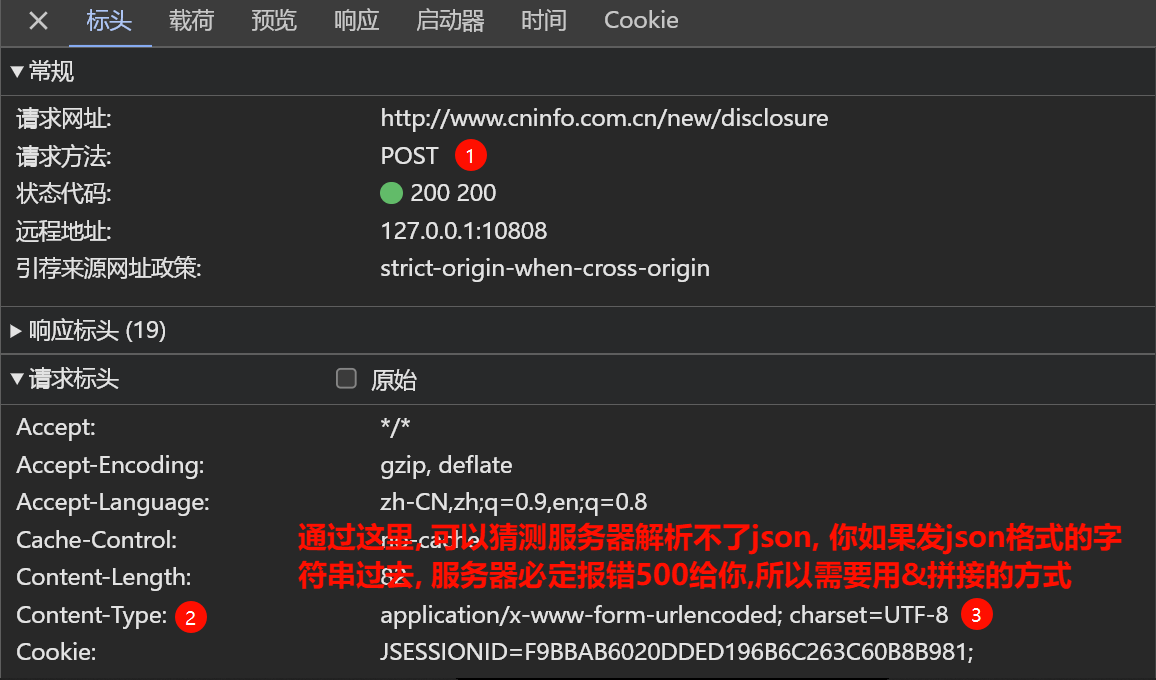
- ! 这里可以查看”请求标头”, 猜测服务器能解析何种请求方式(①json字符串②&符号拼接), 其实不用刻意去背, 其中一种发不了的时候, 用另一种就行
| 类型 | Content-Type | 简要解释 | 使用场景 | 默认该用 |
|---|---|---|---|---|
| 表单数据 | application/x-www-form-urlencoded | 适用于简单的键值对数据,通常用于HTML表单提交。 | 提交表单数据,如登录表单、搜索表单等 | FormRequest |
| JSON数据 | application/json | 适用于结构化数据,广泛用于API开发。 | 提交JSON格式的数据,如API请求 | Request |
| 文件数据 | multipart/form-data | 适用于上传文件,可以同时发送文件和表单数据。 | 上传文件,如图片、文档等 | Request |
| XML数据 | application/xml 或 text/xml | 适用于XML结构化数据,常用于SOAP等协议。 | 提交XML格式的数据,如SOAP请求 | Request |
| 自定义数据格式 | text/plain 或其他自定义类型 | 适用于自定义格式的数据,只要服务器端能够解析即可。 | 提交自定义格式的数据 | Request |
| 多种数据类型混合 | multipart/form-data | 可以在一个请求中混合使用多种数据类型,如表单数据和JSON数据。 | 混合发送多种类型的数据 | Request |
|  |
第八节 中间件 DownloaderMiddlewares
2.8.1 DownloaderMiddlewares
- & 说明: ①可以有很多个”下载中间件” ②类似Spring的”拦截器”,来回都会拦截
from_crawler()- $ 作用: 这个方法初始化该”下载中间件”类, 必须返回 这个中间件的实例对象
- $ 语法点2:
crawler.signals.connect(触发指定方法, 指定情况)像默认写法这里就是, 当spiders对象实例化时(前), 触发一个叫做spider_opened的一个自定义方法 - $ 返回值: 一定是当前类的实例化对象
| 信号名称 | 说明 【数据来源Cursor】 |
|---|---|
| signals.spider_opened | 当爬虫打开时触发。 |
| signals.spider_closed | 当爬虫关闭时触发。 |
| signals.item_scraped | 当一个项目被爬虫成功抓取并返回时触发。 |
| signals.request_scheduled | 当请求被调度器安排时触发。 |
| signals.response_received | 当响应被下载器接收到时触发。 |
| signals.spider_error | 当爬虫处理请求时发生错误时触发。 |
| signals.item_dropped | 当项目被丢弃时触发。 |
| signals.engine_started | 当Scrapy引擎启动时触发。 |
| signals.engine_stopped | 当Scrapy引擎停止时触发。 |
| signals.start_requests | 当爬虫开始请求时触发。 |
| signals.stats_collected | 当统计信息被收集时触发。 |
1 |
|
process_request()- $ 作用: 这个方法用于截取 Engine到Dowloader之间的url请求
- $ 返回值:
- ①【default】
return None: 默认就是返回None, 表示继续发送原先的request请求 - ②
return Request对象: (记形参中的reqeust为”原request”; 返回的request为”新request”)原request不发了=>将”新request加入到请求队列中==>终止原request的生命周期(不再发往下一个request) - ③
return Response对象: 终止request的生命周期(不再发往下一个中间件,更不会发给”下载器”), 示例: Engine->A->B->C->Downloader; ABC分别是不同的下载中间件那如果A的process_request返回Response, 这个Response是直接略过BC的process_request, 直接跳到CBA这个次序的process_response 进行处理
1 | def process_request(self, request, spider): |
process_response()- $ 作用: 截取 Dowloader准备返回给Engine的response信息 (注意如果有多个DowloaderMiddleware顺序与process_reqeust正好相反)
- $ 返回值:
- ①【default】
return Response: 默认就是返回Response,适用于: 可以”篡改”响应内容, 或缓存机制(比如如果request的url相同, 我直接返回缓存中的值类似与”篡改”) - ②
return Reqeust: 适用于: 重定向 或 条件处理(如果返回的response不是200,就换个代理ip重新请求)等- 如果返回Reqeust对象, 那当前的response对象还会被Spider的parse方法接受到吗? 否
- 如果是Engine->A->B->C->Dowloader的次序, C的process_response()直接返回了一个request, BC还能接受到吗? 否
1 | def process_response(self, request, response, spider): |
process_exception()用到再说, 😪😫🥱😴
1 | def process_exception(self, request, exception, spider): |
2.8.2 设置请求头 & Cookies
- 设置请求头
- & 大体思路: DowloaderMiddleware中的process_request()方法既然是拦截请求的, 那我直接在这里把user-agent带上就实现了
- $ 语法;
request.headers['user-agent'] = 字符串 - ! 注意: 这里直接等于字符串, 不是字典,
1 | def process_request(self, request, spider): |
- 设置Cookies
- $ 语法: ①先去
settings.py把COOKIES_ENABLED = False取消注释 ②request.headers['Cookie'] = 字符串 - ! 注意: 一定要去settings.py解开, 要不Scrapy访问默认是不会携带Cookies的
- $ 语法: ①先去
1 | def process_request(self, request, spider): |
2.8.3 设置代理IP 🔒
- & 帮助文档: ①meta ②meta#proxy
- $ 语法: ①proxy的设置: Request对象中有个meta属性, 其下有个proxy属性,
request.meta['proxy']="http://2.2.3.3:4324"②download-timeout属性 - ! 卡点: Scrapy的异步是, 将所有的请求(近乎)同一时刻发出, 所以需要一个”版本锁”/“乐观锁”的思想(Redis的锁)
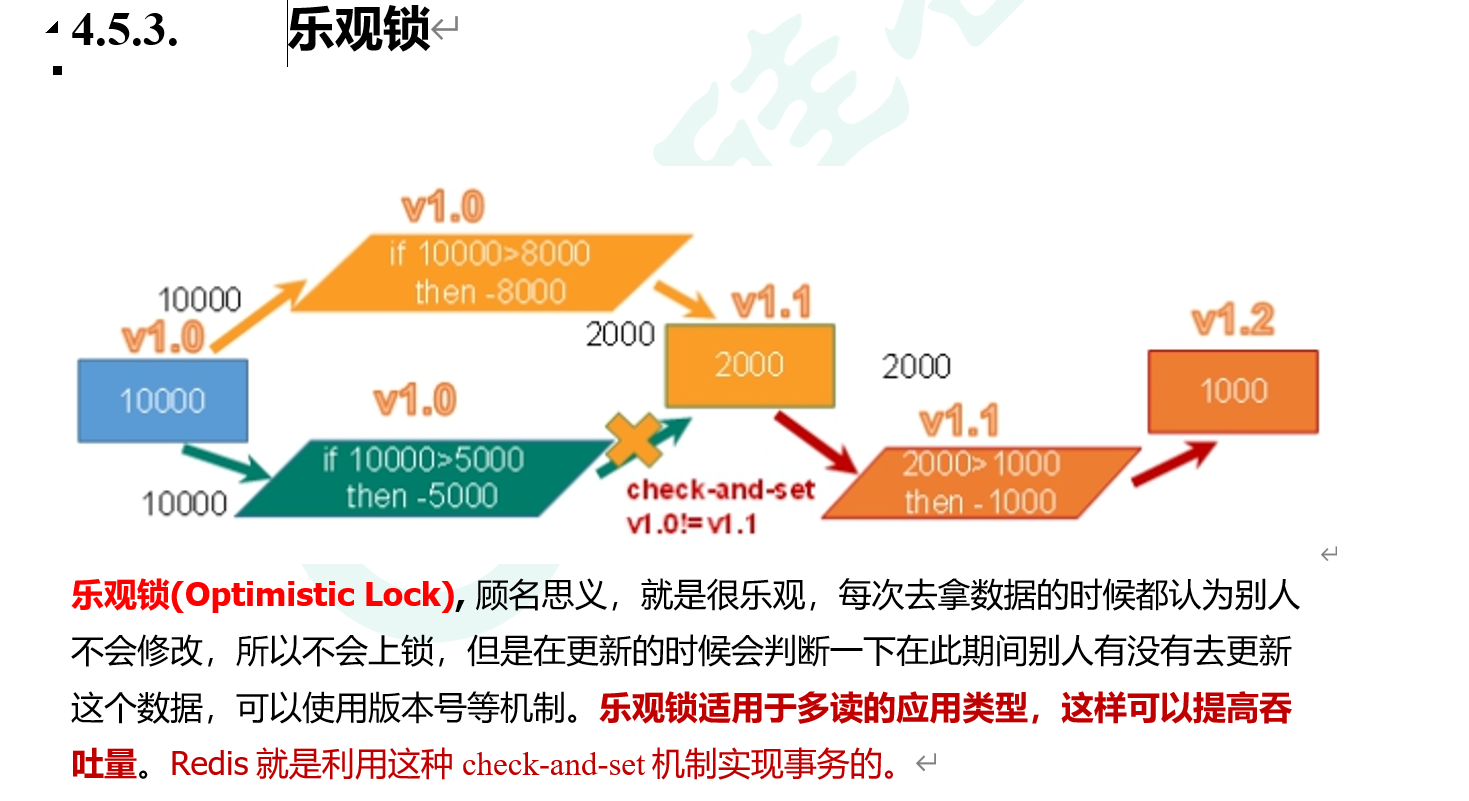
- 错误版本!!!!
1 | # Version_1: 因为异步延迟问题, 导致的ip复用失败 |
- 可重用ip版本
1 | # Version_2: 采用类似"版本锁"的思想, 构建复用单ip |
- 可复用ip代理池
1 | # Version_3: 同Version_2的思想, 构建ip池 |
- 连接Redis的ip代理池
2.8.4 联动Selenium
- & 大体思路: 在DowloaderMiddlewares的process_request()那 ①截获url, ②用Selenium发送, ③并直接返回Response结果 [[11.Scrapy框架#2.1.5 Scrapy框架的工作流程]]
- ! 注意: ①Scrapy中的浏览器驱动必须使用 绝对路径 ②这里的浏览器不会自己关, 必须要quit()
1 | class SeleniumTxWorkDownloaderMiddleware: |
2.8.5 RetryMiddleware重试中间件
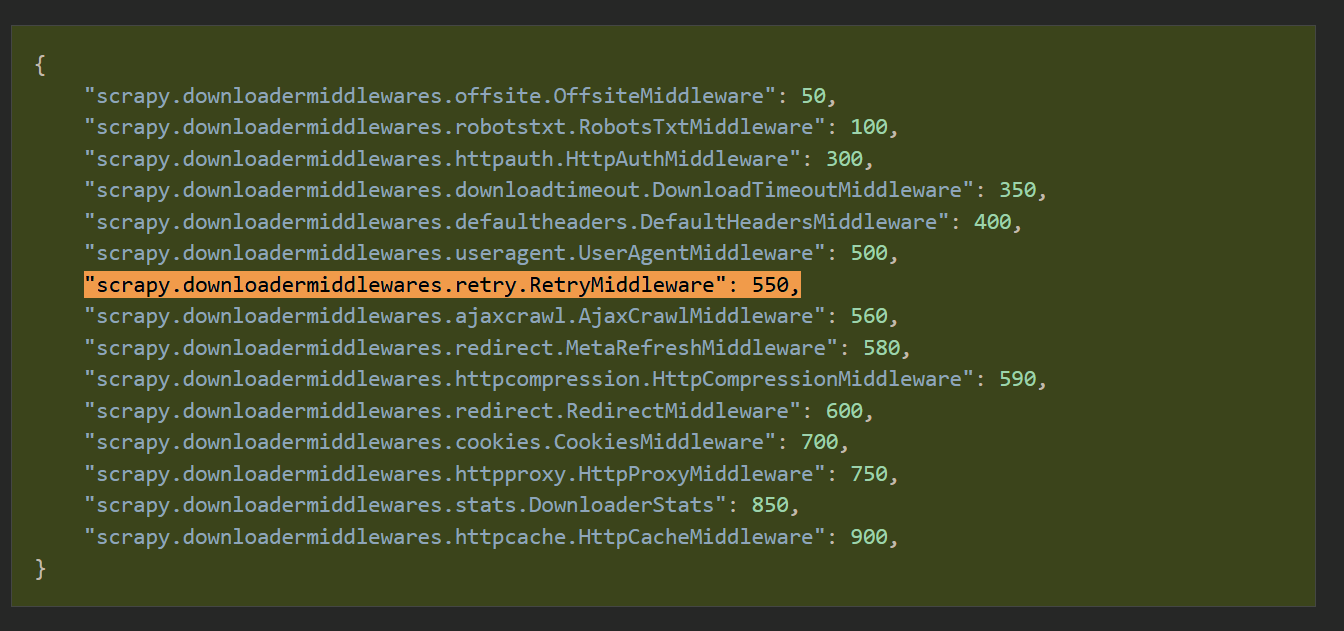
- & 这个是Scrapy默认配置的中间件, 就这个容易晕☠️; 下图是官方中间件的”名称”和”权值”【图一】
- $ 这个中间件的流程如下:

- 检查全局重试开关
→ 若settings.RETRY_ENABLED = False或request.meta['retry_enabled'] = False,直接跳过重试。
→ 若request.meta['dont_retry'] = True,终止重试流程。
- 触发重试条件判断
→ 异常触发:请求抛出异常,且异常类型在settings.RETRY_EXCEPTIONS中。【图二】
→ 状态码触发:响应状态码在settings.RETRY_HTTP_CODES中。【图二】
- 计算最大重试次数
→ 优先级:request.meta['max_retry_times']>settings.RETRY_TIMES(默认 2)。
- 判断当前重试次数
→request.meta['retry_times']记录已重试次数(初始为 0)。
→ 若retry_times >= max_retry_times,停止重试。
- 执行重试
→ 克隆原始请求,retry_times+1,重新加入调度队列。
→ 设置request.dont_filter=True==防止被过滤==
- $ 关键属性/配置作用
request.meat['dont_retry']:强制跳过某请求的重试。request.meat['max_retry_times']:单请求最大重试次数的局部覆盖。request.meat['retry_times']:统计当前重试次数。RETRY_ENABLED:settings.py中配置, 全局重试开关。RETRY_HTTP_CODES:settings.py中配置, 需重试的 HTTP 状态码列表。RETRY_EXCEPTIONS:settings.py中配置, 需重试的异常类型列表。
第九节 Scrapy爬虫监控
2.9.1 使用监控平台ScarpyOps
- STEP1: 下载包
1 | pip install scrapeops-scrapy |
- STEP2: 获取Accout API Key
- $ ScrapyOps监控平台 https://scrapeops.io/app/jobs
- $ ScrapyOps监控平台 https://scrapeops.io/app/jobs

- STEP3:
settings.py
1 | EXTENSIONS = { |
1 | DOWNLOADER_MIDDLEWARES = { |
1 | SCRAPEOPS_API_KEY = 'YOUR_API_KEY' |
2.9.2 发送邮件
- STEP1:
settings.py
1 | EXTENSIONS = { |
1 | # 邮箱 |
- STEP2: spider编写
1 | class TxWorkSpider(scrapy.Spider): |
第十节 总结常用设置
2.10.1 Request对象
| 属性 | 作用 | 默认值 | 注意 |
|---|---|---|---|
request.header['user-agent'] | 设置本次请求的UA头 | 无 | |
request.header['cookie'] | 设置本次请求的Cookie内容; | 无 | settings.py中的COOKIES_ENABLED = False必须设置 |
request.meta['proxy'] | 设置请求的代理IP | 无 | |
request.meta['download_timeout'] | 最长等待该请求响应的时间 | 180s | |
request.meta[retry_times'] | 是第几次重试 | 0 | 首次发送不算重试, 首页也就没有这个属性 |
request.meta['max_retry_times'] | 最多重试几次 | 2 | 设置为3, 该请求会发4次, 因为首次不算重试 |
request.dont_filter | 是否将该URL进行过滤 | False | 默认是会过滤的 |
2.10.2 settings.py
- & 说明: 这里只列举, 不是每次都用到, 但可能会用到的配置属性
| 属性 | 作用 | 归属 | 默认值 | 注意 |
|---|---|---|---|---|
| DOWNLOAD_DELAY | 每个请求之间的延迟时间(秒) | Request | 0 | |
| RETRY_DELAY | 重试请求之间的延迟时间(秒) | Request | 3 | |
| CONCURRENT_REQUESTS | Scrapy同时可以处理的请求数目 | 全局 | 100 | |
| CONCURRENT_REQUESTS_PER_IP | 每个IP同时发起的请求数量 | 全局 | 8 | 当请求的IP相同数量到达CONCURRENT_REQUESTS_PER_IP 后, 后续使用该iP的请求, 会等其前面(使用该IP的)请求完成处理后, 再请求 |
- 关于
CONCURRENT_REQUESTS_PER_IP的Q&A:
1 | 问题: 10个请求, 使用同一个IP(CONCURRENT_REQUESTS_PER_IP=8), scrapy会如何调度 |
第三章 分布式爬虫scrapy_redis
第一节 初识scrapy_redis
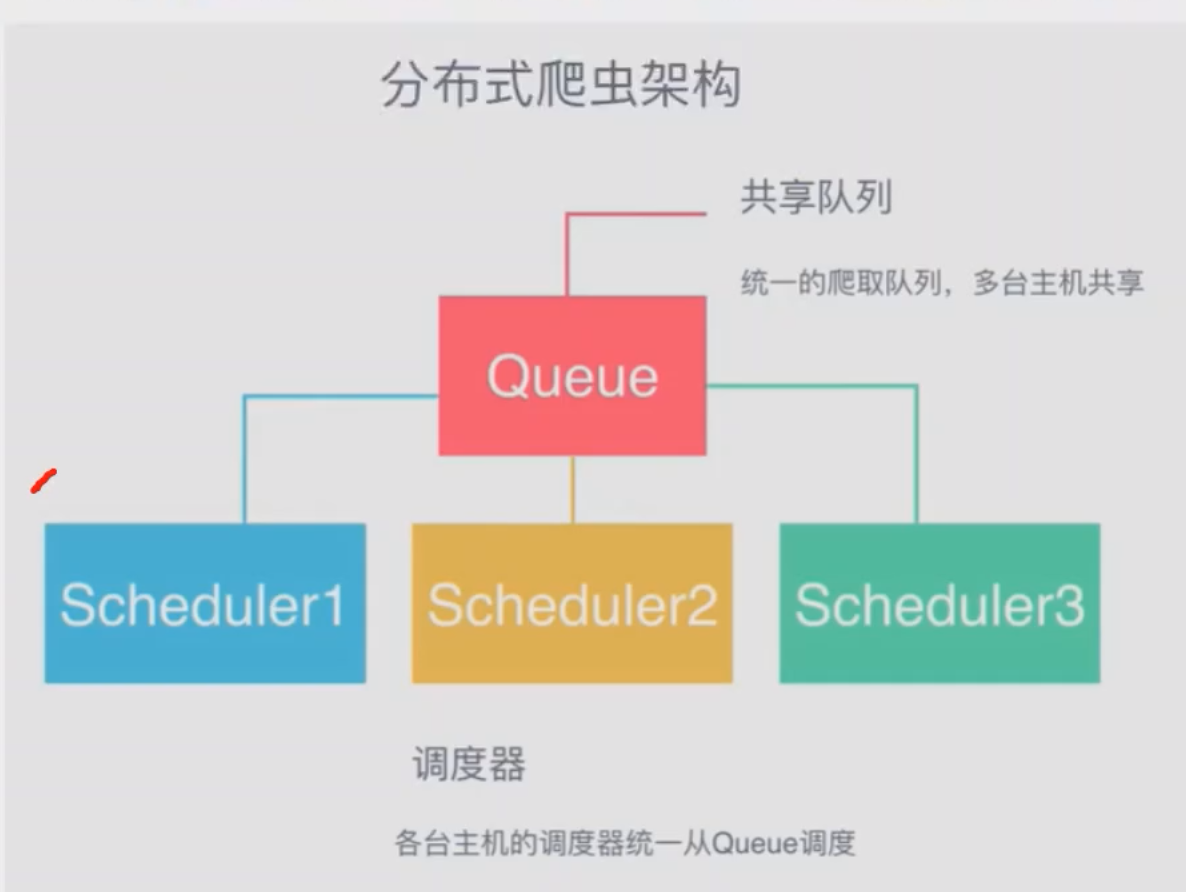
3.1.1 分布式爬虫的架构(基本思想)
scrapy_redis地址: https://github.com/rmax/scrapy-redis
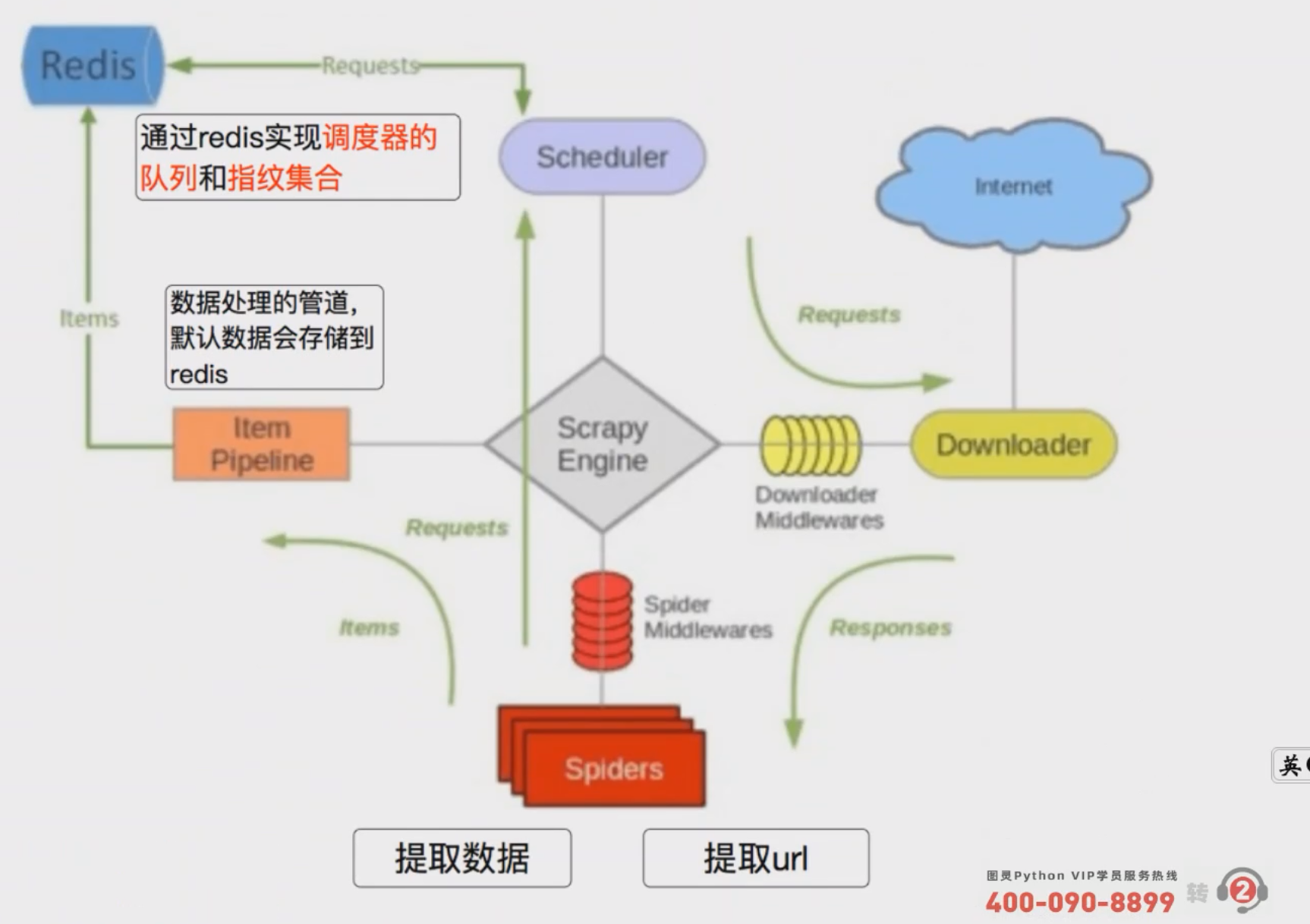
- & 说明: 因为是分布式, 所以是多个Scheduler同时进行调度①【图一】可以选择用Queue,但因为Queue没办法实现共享 ② 【图二】所以用Redis实现数据的共享; 而这个Redis也不用我们自己实现, 有
scrapy_redis帮我们写好了, 我们直接用就好 - $ 总结: 使用
scrapy_redis后在Redis中可能会存在以下键REDIS_KEY:request: 所有的yield scrapy.Request(...)会上传到Redis的这个键中, 所有的请求会从这个键中拿REDIS_KEY:dupefilter: 开启过滤后该集合会将所有的URL进行SA1 Hash编码, 用于判重REDIS_KEY:items: 如果配置scrapy_reids的管道就会存储到redis中'scrapy_redis.pipelines.RedisPipeline': 400
第二节 Hello Scrapy_Redis
STEP1: settings.py配置
- $ 语法: 包括①换调度器 ②换过滤器 ③开启断点续爬 ④配置Redis连接URL
1 | SCHEDULER = 'scrapy_redis.scheduler.Scheduler' # 换调度器 |
STEP2: spider配置
- & 说明: 实际上只需要STEP1就可以联动Redis了, 但如果要涉及多台机器, 就必须要配置STEP2, 配置后会有以下变化
- ①spider监听
REDIS_KEY:request键是否有值 , 如果有会从该键中拿, ==否则不会关闭, 而是监听这个端口==(如果只配STEP1, 键中没值就退出程序)
- ①spider监听
1 | class Top250RedisSpider(scrapy_redis.spiders.RedisSpider): # 换基类 |
第三节 深度理解两个Redis中的键
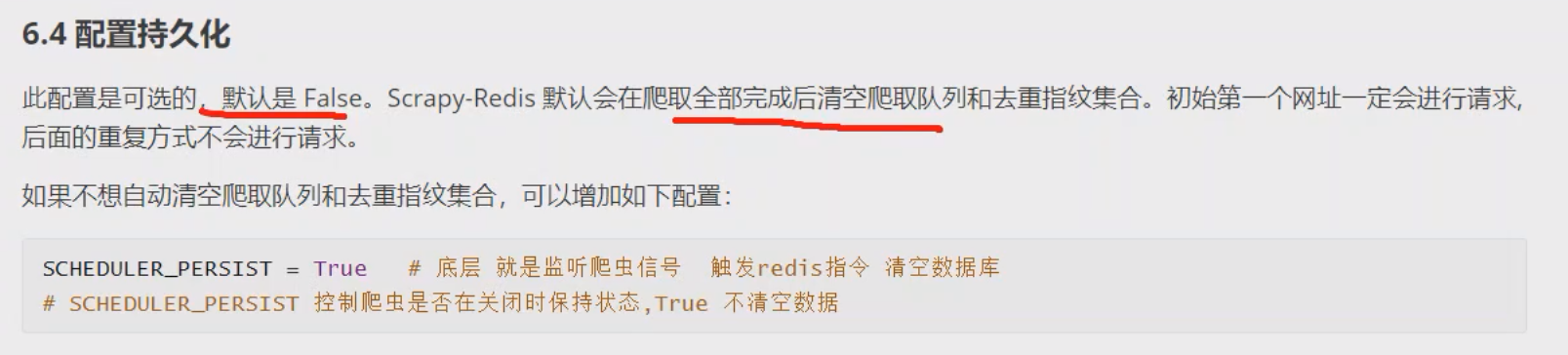
3.3.1 REDIS_KEY:request
- & 作用: 断点续爬就是靠这个, 相当于原生断点续爬的crawls目录下的文件
- $ 如下两个属性可以看看, 注意只是知道即可, 不要乱用, 贼容易晕😵💫

3.3.2 REDIS_KEY:dupefilter
- & 说明: 如果URL的
request.dont_filter属性为True就不会进到这里进行去重, 否则会去重, 和原生的一样
- Title: 11.Scrapy框架
- Author: 明廷盛
- Created at : 2025-02-15 14:34:49
- Updated at : 2025-02-15 13:41:00
- Link: https://blog.20040424.xyz/2025/02/15/🐍爬虫工程师/第一部分 爬虫基础/11.Scrapy框架/
- License: All Rights Reserved © 明廷盛