
12.Feapder

我的评级:不好用, 中间件只能拦截发送的, 不能拦截返回的, 就nm离谱, 帮助文档写的也模糊, 既然有中间件, 为什么整体流程中不标注???用Scrapy
第一章 Feapder基本知识
第一节 为什么使用Feapder
1.1.1 关于Feapder
官方文档: https://feapder.com/#/
- 异步爬虫框架(底层是asyncio, aiohttp实现异步)
- 国内的框架, 源码注释, 帮助文档都是中文
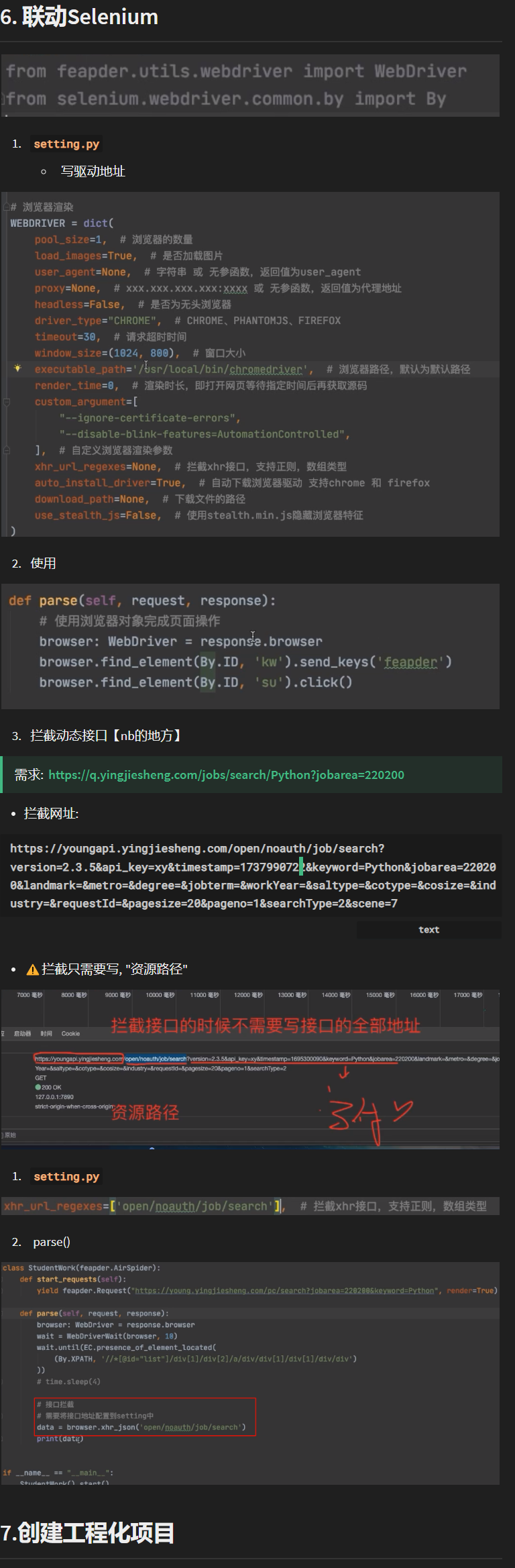
- ==底层封装了Selenium, 并且支持Selenium拦截xhr请求结果==
- & 这个框架我不会花很多时间, 像什么工作流程我就不去管了,如果后面学完分布式后, 发现比Scarpy好用, 会详细学的
- & 现在主要了解下①UA,Cookie, 代理IP的携带 ②Selenium拦截xhr请求结果
1.1.2 下载Feapder框架
- & 说明: 这里是全量下载, 具体区别
1 | pip install "feapder[all]" |
第二节 Hello Feapder
需求: 爬取“豆瓣”电影信息
STEP1: 创建项目&轻量级爬虫文件
1 | feapder create -p douban # 这个指令会在当前文件夹下, 生成项目文件"douban" |
STEP2: 配置数据库,并生成表对应的Item文件
- $ 语法: feapder需要先去数据库生成表, 不能像scrapy那样在爬虫代码中建表
1 | # MYSQL |
1 | feapder create -i db_movie # cd到Item文件夹下, 后续选择第一个Item即可 |
STEP3: 编写具体spider实现数据清洗
- $ 语法:实例化Item对象:
item = db_movie_item.DbMovieItem() - $ 语法: Scrapy中的meta字典, 这里是item直接传递
- $ 语法: 启动可以多
1 | import feapder |
第三节 中间件(下载中间件)
1.3.1 配置UA
第四章 Selenium拦截
- Title: 12.Feapder
- Author: 明廷盛
- Created at : 2025-02-15 14:34:49
- Updated at : 2025-02-15 15:34:00
- Link: https://blog.20040424.xyz/2025/02/15/🐍爬虫工程师/第一部分 爬虫基础/12.Feapder/
- License: All Rights Reserved © 明廷盛