3.爬虫基础

第一章 爬虫基本概念
爬虫成功案例: 今日热榜
第一节 爬虫分类
- 通用爬虫: 类似百度搜索, 全网爬取
- 聚集爬虫: 对特定网页进行爬取
第二节 爬虫基本流程

==第二章 HTTP基本原理==
==第一节 URL概念==
- HTTPS对比HTTP: S是多了层SSL层, 解析比HTTP慢
第三章 网页调试工具的使用
常看常新!!!
第一节 打开Cookie
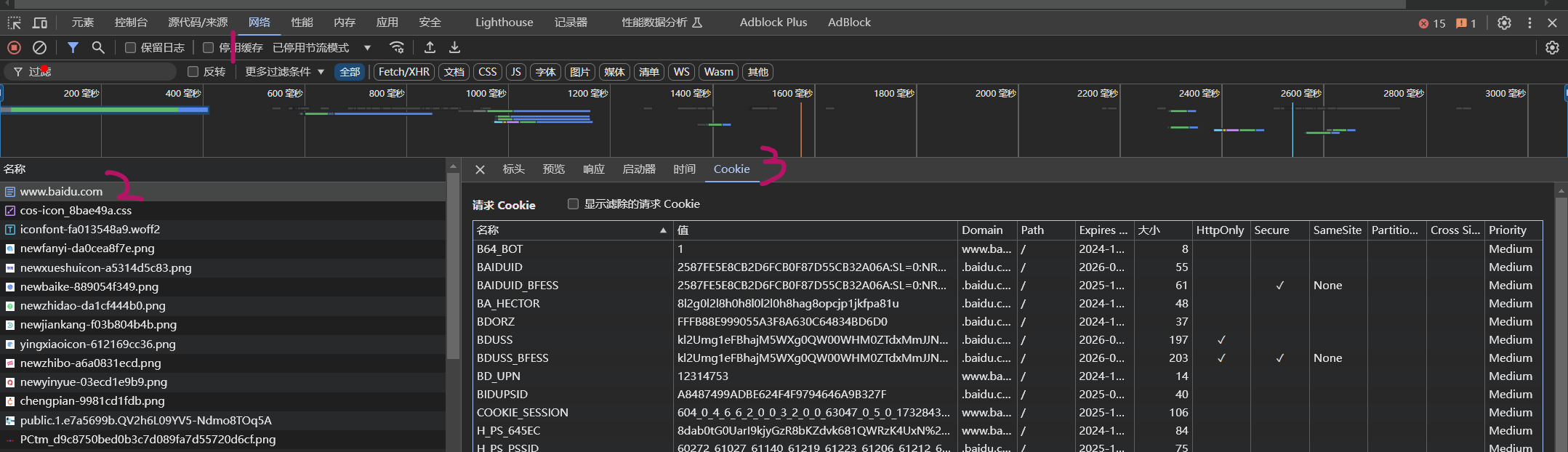
第二节 关于Cookie中的HttpOnly字段
如果打钩, 说明是服务器设置的coookie

第四章 HTTP请求形式
第一节 请求
- 概念: 由客户端向服务端发出
- 组成: ①请求方法(tequest Method) ②请求的网址 (Request URL) ③请求头(Request Headers) ④请求体(Request Body)
- 为什么要记住这个?: 很少让你这么手动拼接(除了socket的实现方式) 需要注意记住“空格 “;“回车符\r”;“换行符\n”;“冒号:”
第五章 Cookie
==第六章 三种爬取页面资源的方式==
需求: 爬取目标网页的图片: https://image11.m1905.cn/uploadfile/2021/0922/thumb_0_647_500_20210922030733993182.jpg
第一节 使用socket实现
作用: 客户端使用socket完成类似于浏览器访问网站的一个程序
6.1.1 STEP1: 实例化socket对象
1 | # 6.1.1 STEP1: 实例化socket对象 |
6.1..2 STEP2: 与网站建立连接 connect()
- 语法:
connect((host, port))
1 | # 6.1..2 STEP2: 与网站建立连接 `connect()` |
6.1.3 STEP3: 发送请求 send()
- 语法:
send(二进制数据)这里只能接受二进制数据,使用encode()可以将 字符串=>二进制
1 | # 6.1.3 STEP3: 发送请求 `send()` |
6.1.4 STEP4: 获取网站返回的信息 recv()
- 语法:
recv(读一次需要读多少kb的数据)
1 | res = b"" # 二进制的数据 |
6.1.5 STEP5: 对返回的信息进行处理
- 这里设计的re包后面章节细说
1 | # 6.1.5 STEP5: 对返回的信息进行处理 |
第二节 使用urllib3实现
urllib3是python自带的
6.2.1 STEP1: 实例化HTTP连接池
1 | # 6.2.1 STEP1: 实例化HTTP连接池 |
6.2.2 STEP2: 请求网站资源request()
1 | # 6.2.2 STEP2: 请求网站资源 |
6.2.3 STEP3: 对返回的信息进行处理
1 | # 6.2.3 STEP3: 对返回的信息进行处理 |
==第三节 使用requests实现==
①requests需要自己下载 ②不是HttpServletRequest-_-!
6.3.1 STEP1: 请求网站资源get()并获取response
1 | # # 6.3.1 STEP1: 请求网站资源`get()`并获取response |
6.3.2 STEP2: 对返回的数据进行处理
1 | # 6.3.2 STEP2: 对返回的数据进行处理 |
第X节 作业
- 使用urllib3一次性爬取以下三张图片
1 | https://pic.netbian.com/uploads/allimg/220211/004115-1644511275bc26.jpg |
- Title: 3.爬虫基础
- Author: 明廷盛
- Created at : 2025-02-15 14:34:49
- Updated at : 2025-02-15 15:26:00
- Link: https://blog.20040424.xyz/2025/02/15/🐍爬虫工程师/第一部分 爬虫基础/3.爬虫基础/
- License: All Rights Reserved © 明廷盛