5.数据提取方式(json,正则)

第一章 数据提取的概念和数据分类
在爬虫爬取的数据中有很多不同类型的数据,我们需要了解数据的不同类型来又规律的提取和解析数据。
- 结构化数据:
json、xml- 处理方式:直接转化为
python数据类型
- 处理方式:直接转化为
- 非结构化数据:
HTML- 处理方式:正则表达式
re包、xpath、bs4
- 处理方式:正则表达式
第二章 转化json数据json包
第一节 字典 与 json格式字符串 的转换
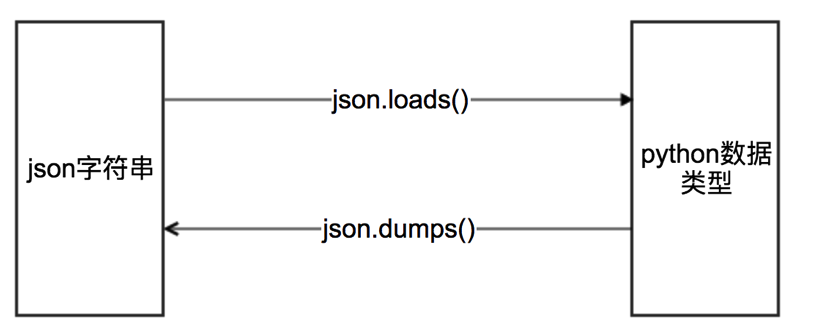
语法: ①
字符串=dumps(字典)②字典=loads(字符串)助记: 1. s表示字符串 2.dump是垃圾的意思, dict比json要高级, 所以转成json垃圾要用dump
1
2
3
4
5
6
7
8# # 字符串与json
user_input = {"name": "双双", "age": "18"} # 字典
res = json.dumps(user_input, ensure_ascii=False, indent=4) # 字典=>json字符串
print(res)
# json字符串=>字典
dict = json.loads(res)
print(dict, type(dict))
第二节 文件 与 json格式字符串
语法: ①写:
json.dump(字符串, 文件f)②读:字典=json.load(文件f)1
2
3
4
5
6
7
8
9# dict写入json格式的文件
user_input = {"name": "双双", "age": "18"} # 字典
with open("./json/test.text", "w") as f:
json.dump(user_input, f)
# 从json格式的文件读取dict
with open("./json/test.text", "r") as f:
my_dict = json.load(f)
print(my_dict, type(my_dict))
第三节 练习:蜻蜓FM排行榜信息
蜻蜓FM的首页url:https://m.qingting.fm/rank
代码示例:
1 | import requests |
分析过程:
第三章 正则表达式re包
工具链接地址:https://regexr-cn.com 在这个工具中我们可以快速验证自己编写的正则表达式是否存在语法错误。
第一节 前置知识
3.1.1 什么是正则表达式
- 定义:用事先定义好的一些特定字符,及这些特定字符的组合,组成一个规则字符串, 这个规则字符串用来表达对字符串的一种过滤逻辑。
3.1.2 ASCII码与正则表达式
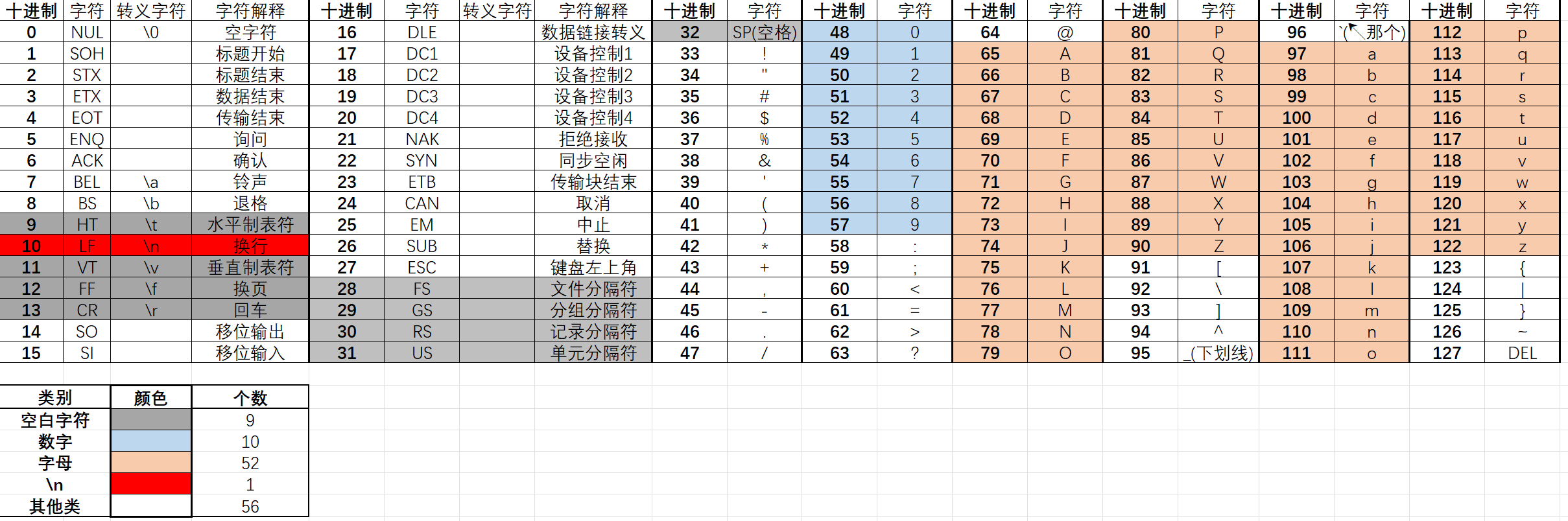
- 为什么要提ASCII码: 正则表达式默认是在128个ASCII码的范围内的*(当然后面可以指定Unicode去做中文匹配)*, 而其匹配规则是将这128个ASCII进行了分类的, 不同的规则符号控制不同的类匹配, 所以弄清楚正则表达式是如何将128个ASCII码分类的是十分重要的, 关乎到匹配是否完全, 是否不重不漏!!!
3.1.3 关于字符串的基本知识
第二节 单个字符匹配
| 单字符 | 匹配规则 | 表达式 | 完整匹配的字符串 |
|---|---|---|---|
. | 匹配任意除换行符\n外的字符 | a.c | abc |
\d | 数字:[0-9] | a\dc | a1c |
\D | 非数字:[^\d] | a\Dc | abc |
\s | 空白字符:[<空格>\t\r\t\f\v] | a\sc | a c |
\S | 非空白字符:[^\s] | a\Sc | abc |
\w | 单词字符:[A-Za-z0-9_] | a\wc | abc |
\W | 非单词字符:[^\w] | a\Wc | a c |
* | 匹配前一个字符0次或者无数次 | abc* | ab、abccccc |
+ | 匹配前一个字符1次或者无数次 | abc+ | abc、abccccc |
? | 匹配前一个字符0次或者1次 | abc? | ab、abc |
{m} | 匹配前一个字符m次 | ab{2}c | abbc |
[...] | 字符集(字符类)。对应的位置可以使字符集中任意字符。字符集中的字符可以逐个列出,也可以给定范围:[abc]或[a-c]。第一个字符如果是^则表示取反:[^abc]表示不是abc的其他字符 | a[bcd]e | abe、ace、ade |
\ | 转义字符,使后面一个字符改变原来的意思。如果字符串有字符*需要匹配,则可以使用\* | a\.c | a.c |
3.2.1 任意字符匹配(\n) .
语法:
.作用: 可以代表**任意** 一个字符(除了\n)
匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) √ √ √ ==×== √ 举例: ①规则:
"pers.n"②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])len(res)=127 除了\n都匹配成功 ② “personpers\\nn” [‘person’, ‘pers\n’] “pers\\n”中的两个转义\\=>\ ③ r’personpers\nn’ [‘person’, ‘pers\\n’] “pers\n”可以匹配, 但输出是以字符串输出, 不能r(原始字符串), 所以要转义一个斜杠, 控制台输出时才会看起来多一个斜杠 ④ “pers$n” [‘pers$n’] 只要不是\n都可以匹配 ⑤ “pers\nn” [] 没+r, \n是匹配不上的转义字符, 无法匹配 ⑥ “pers\an” [‘pers\x07n’] 没+r, 只要不是\n都可以匹配, 这里\x07是(两位16进制)转义为7, 对应ASCII表中的第七个(十进制)=>\a 响铃 注意⚠️: 如果举例第②③⑥个看不懂了, 一定要去把前置知识第三个点回顾下
3.2.2 数字匹配 \d
语法:
\d作用: 匹配**一个** 数字([0-9])
匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) ==×== √ ==×== ==×== ==×== 举例: ①规则:
"\dabc"②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])除了10个数字, 都不能匹配 ② ‘a0abc’ [‘0abc’]
3.2.3 非数字匹配 \D
语法:
\D作用: 匹配**一个** 非数字(
[0-9])匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) √ ==×== √ √ √ 举例: ①规则:
"\Dabe"②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])除了10个数字, 都匹配 ② “7&abe” [‘&abe’]
3.2.4 空白匹配 \小s
语法:
\s作用: 匹配**一个** **空白字符(
\t\v\f\r分隔符*4空格)**或 \n匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) √ × × √ × 举例: ①规则:
"hello\sworld"②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])correct:10 error:118 ② ‘hello\tworld’ [‘hello\tworld’] \t ③ ‘hello\nworld’ [‘hello\nworld’] \n ④ ‘hello world’ [‘hello world’] 空格
3.2.5 非空白匹配 \大S
语法:
\大S作用: 匹配**一个** 非空白字符, 匹配不了\n
匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) ==×== √ √ ==×== √ 举例: ①规则:
"\Sabc"②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])correct:118 error:10 ② ‘\nabc’ [] 匹配不了\n ③ ‘#$abc’ [‘$abc’] 其他类 中的都可以
3.2.6 单词匹配 \小w
语法:
\小w作用: 匹配 一个 字母 数字 或 其他类中的”_” 或 中文字符(涉及到Unicode)
匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) 中文字符 ==×== √ √ ==×== ==×== "_"√√ 举例: ①规则:
'双双\w三斤'②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])correct:63 error:65 ② ‘双双胖三斤’ [‘双双胖三斤’] 中文字符也可以 ③ ‘双双p三斤’ [‘双双p三斤’] ④ ‘双双pp三斤’ [] 一个 ⑤ ‘双双_三斤’ [‘双双_三斤’] “_”其他类中只有下划线可以
3.2.7 非单词匹配 \大W
语法:
\大W作用: 匹配 一个 空白字符 或 \n 或 其他类中除”_”的其他字符
匹配:
空白字符(9) 数字(10) 字母(26*2=52) \n(1) 其他类(56) 中文字符 √ ==×== ==×== √ √ "_"×举例: ①规则:
"双双\W三斤"②方法findall()序 需要匹配的字符串 输出结果 解释 ① "".join([chr(i) for i in range(128)])correct:65 error:63 ② ‘双双胖三斤’ [] 中文字符 NO! ③ ‘双双p三斤’ [] 字母 NO! ④ ‘双双pp三斤’ [] 字母 NO! 不是第一个 NO! ⑤ ‘双双_三斤’ [] “_” NO! ⑥ ‘双双#三斤’ [‘双双#三斤’] 其他字符 YES! ⑦ ‘双双\n三斤’ [‘双双\n三斤’] \n YES!
第三节 多个字符匹配
3.3.1 字符数量匹配 * + ? {m}
语法:
- ①只有和
[]连用时, 才将[]看做一个字符, 比如finditer("[a-g]*", "abcdefgg")就是a-g可以出现0~♾️次 - ②其他时候, 都是针对, 前一个字符, 比如
finditer("abcdefg*", "abcdefgg")是只a-f固定, 只有末尾的g可以出现0~♾️次
单字符 匹配规则 表达式 完整匹配的字符串 *匹配前一个字符0次或者无数次 abc*ab、abccccc+匹配前一个字符1次或者无数次 abc+abc、abccccc?匹配前一个字符0次或者1次 abc?ab、abc{m}匹配前一个字符 m次ab{2}cabbc- ①只有和
注意⚠️: ==是前一个字符, 不是前一个单词==
举例: ①规则:每个不同注意看 ②方法
findall()序 规则 需要匹配的字符串 输出结果 规则含义 ① “abc*” “abcab” [‘abc’, ‘ab’] ab开头就可以 ==②== “abc*” “abacab” [‘ab’, ‘ab’] ab开头就可以, 但必须以ab开头 ==③== “[a-g]*” “abcdefgg123” [‘abcdefgg’, ‘’, ‘’, ‘’, ‘’] a-g可以出现0~♾️次, 所以对于1,2,3,分别出现0次, 匹配0次出现 ''④ “abcdefg*” “abcdefgg123” [‘abcdefgg’] a-f固定, 只有末尾的g可以出现0~♾️次, 只有一个 ==⑤== “[a-z]*” “abcdef123” [‘abcdef’, ‘’, ‘’, ‘’, ‘’] 'abcdef'是因为[a-z]中的[a-f]出现了一次符合*, 后面三个的理解同③==⑥== [a-z123]* “abcdef3211” [‘abcdef3211’, ‘’] [a-z123]*表示匹配任意数量(包括0个)的小写字母或数字1、2、3的组合。这意味着它可以匹配空字符串,也可以匹配任何由小写字母和/或数字1、2、3组成的字符串==⑦== [a-z123]{2} “abcdef3211” [‘ab’, ‘cd’, ‘ef’, ‘32’, ‘11’] 综合来看, [a-z123]{2}表示匹配任意两个连续的小写字母或数字1、2、3的组合。这意味着它可以匹配任何由两个小写字母和/或数字1、2、3组成的字符串, 顺着走, 不会头匹配是正则的特点, 所以够两个就算匹配到了一个结果
3.3.2 字符集 [...]
语法: 对应的位置可以使字符集中任意一个字符。字符集中的字符可以逐个列出,也可以给定范围:
[abc]或[a-c]。第一个字符如果是^则表示取反:[^abc]表示不是abc的其他字符举例: ①规则:
"a[bcd]e"②方法findall()注意⚠️: 不要用空格隔开!!!
序 需要匹配的字符串 输出结果 解释 ① “abeaceade” [‘abe’, ‘ace’, ‘ade’]
3.3.3 以什么开头/结尾 ^ $
3.3.4 转义特殊正则字符 \
语法:
\作用: 用与匹配 一个
.(原任意字符)*(原0和无数次)+(原1和无数次)?(原0次和1次)举例: ①规则: ②方法
findall()序 匹配规则 目标字符串 输出结果 解释 ① "\\\\""\\"(就是一个\, 因为两个反斜杠是用于转义=>一个反斜杠)['\\']匹配规则中其实是两个反斜杠, 第一个反斜杠用于转义第二个, 所以是匹配有一个反斜杠的目标字符 ② "\.""."['.']③ "\.""\&"[]这个.可不是任意, 转义后, 只能匹配.
第四节 分组匹配
3.4.1 分组对象 <class '_sre.SRE_Match'>
类型: 这个是re包中的一个类型
常用方法:
方法名称 描述 group()返回正则表达式匹配的整个字符串。 group(n)返回正则表达式中第 n个子组匹配的字符串。默认0=group()start()返回匹配结果的起始位置。 end()返回匹配结果的结束位置。 span()返回一个元组,包含匹配结果的起始和结束位置。 为什么要分组, 分组有什么用?
1
2
3
4
5# 邮箱匹配:比如这里就可以知道什么什么邮箱
# 分组的の作用: 就可以单独获取每个组匹配的内容;
result = re.finditer('\w{4,20}@(163|126|gmail|qq)\.com', '[email protected]')
for i in result:
print(i.group(1)) # 输出结果: gmail
3.4.2 管道符|
3.4.3 引用分组\num
- 语法:
\num①注意转义(一般是两个\\num) ②可以不再组内使用

1 | # 需求一: ①匹配html中的一组标签 ②同时打印是什么标签 |
1 | # 需求二: ①匹配html中的两组标签 ②同时打印是什么标签 |
3.4.4 分组别名(?P)
- 语法:
(?P)注意:①必须在组内命名(是新的组) ②必须在组内引用(但引用不是新的组, 无法获取)

1 | # 需求二的另一种实现方式: ①匹配html中的两组标签 ②同时打印是什么标签 |
3.4.5 强制不使用(捕获)组(?:)
- 语法: 非捕获组的语法是在圆括号内部的模式前加上
?:,这表示该组仅用于匹配,但**不捕获匹配的内容,也不会分配组号**。
1 | # 注意⚠️: 当规则中有组的时候, 只返回组的内容, 并不会返回整个的内容 |
第五节 其他匹配
3.5.1 中文匹配r'[\u4e00-\u9fa5]+'
3.5.2 贪婪模式和非贪婪模式
- 语法: ①只有多个字符匹配的时候才用的到
- 助记: ?限制他不让他贪婪,
第六节 re模块常用方法
re包中的匹配就是单纯的一个个对照, 不是KMP, 不找子串, 不找重复, 匹配不上就下一个
- ①所以当只匹配一个时, 匹配不上, 就是结束匹配,
- ②当匹配多个的, 匹配不上, 就从那个位置继续往下匹配, 不会回头再找重叠的
3.3.1 从头匹配match()
语法:
match("正则表达式的规则", "需要匹配的字符串")返回值:
<class '_sre.SRE_Match'>简称为匹配对象说明: ①强制从头开始匹配 ②只匹配一个
举例: ①规则为”mts” ②方法为
match()需要匹配的字符串 输出结果 解释 “mtss” mts “mmts” None 因为第一个是m符合, 下一个是m不是t, 结束匹配返回None “.com.mts” None 从头开始,第一个不对就结束了 “mts.com.mts” mts 找到就结束, 找到一个就结束了, 尽管后面还有 1
2
3
4
5result = re.match("mts", "mts.com.mts")
print(result.group()) # 结果为"mts";
result = re.match("mts", ".com.mts")
print(result.group()) # 无匹配结果,返回None,调用报错
3.3.2 查找一个 search()
语法: 同
match()search("正则表达式的规则", "需要匹配的字符串")返回值:
<class '_sre.SRE_Match'>说明: ①整段匹配(不一定从头, 有就匹配) ②只匹配一个
1
2result = re.search("667", "776,667,667")
print(result.group()) # 输出结果:667 尽管后面还有
3.3.3 查找全部 findall()
语法:
findall("正则表达式的规则", "需要匹配的字符串")返回值:
<class 'list'>列表, 其中每个元素为匹配的结果
说明: ①整段匹配 ②匹配多个
注意:⚠️:
findall()在规则中存在(捕获)组的时候, 只是返回组内容1
2
3
4
5
6
7
8# 需求: 匹配所有含"667"的字符
result = re.findall("667", "776,667,667")
print(result) # ['667', '667'] 将所有能匹配的都匹配了
# 注意⚠️: 当规则中有组的时候, 只返回组的内容, 并不会返回整个的内容
users_email = "[email protected]#[email protected]#[email protected]"
result = re.findall("(\w{4,20})@(qq|gmail|163|126|sina)\.com", users_email)
print(result) # [('12345', 'qq'), ('wocwoc', 'gmail'), ('tbltbl', '163')]
3.3.4 查找全部返回迭代器 finditer()
语法:
finditer("正则表达式的规则", "需要匹配的字符串")返回值:
<class 'callable_iterator'>可以理解为匹配对象的列表(不是真列表,是一个可迭代的类型)作用: 对比
findall(), 不仅可以找到, 还可以找到每个那段匹配, 组值等 // 我一般用findall(), finditer()用于检查说明: ①整段匹配 ②匹配多个 ③返回多个
<class '_sre.SRE_Match'>类型的迭代器 ④规则存在分组时不会和findall()一样1
2
3
4
5
6
7
8
9
10
11# 需求: ①匹配users_email(字符串)的邮箱 ②获取是字符串的那些段匹配 ③获取都有哪些邮箱后缀
users_email = "[email protected]#[email protected]#[email protected]"
result = re.finditer("\w{4,20}@(qq|gmail|163|126|sina)\.com", users_email)
for i in result:
print(i.span(), ":", i.group(), "后缀是:", i.group(1))
""" 输出结果
(0, 12) : [email protected] 后缀是: qq
(13, 29) : [email protected] 后缀是: gmail
(30, 44) : [email protected] 后缀是: 163
"""
3.3.5 规则定义模型complie()
语法:
complie("正则表达式的规则")返回值:
<class '_sre.SRE_Pattern'>规则类型, 也是上面4个方法的第一个参数需要传递的类型说明: 定义一个规则, ①可以直接用于匹配 ②也可以作为规则传入
1
2
3
4
5users_email = "[email protected]#[email protected]#[email protected]"
patten = re.compile("\w{4,20}@(?:qq|gmail|163|126|sina)\.com") # 用于定义一个匹配规则
print(patten.findall(users_email)) # 可以直接用它调用方法
print(re.findall(patten, users_email)) # 也可以当成规则传入
3.3.6 替换 sub()
语法:
sub("正则表达式的规则", "替换为什么", "目标替换文本")返回值:
<class 'str'>普通的字符串类型, 为替换后的文本说明: ①和
str.replace()原生的替换比起来, 就是可以正则替换1
2
3result = re.sub("maoliang", "<forbidden>", "wo zui xi huan maoliang la , maoliang")
print(type(result))
print(result) # wo zui xi huan <forbidden> la , <forbidden>
3.3.7 自动转义特殊正则字符 escape()
语法:
result=escape("存在特殊字符")将所有的特殊字符进行转义返回值:
<class 'str'>作用: 省去了一个手写转义的麻烦
说明: 很有用, PAT那题就因为这个, 没有考虑到违禁词中存在特殊正则字符
1
2
3
4
5
6
7
8
9
10# 帮你自动完成对特殊正则字符转义
print(re.escape(".*{m}+^&")) # "\.\*\{m\}\+\^\&"
# 不转义无法匹配
result = re.findall(".*{m}+^&", ".*{m}+^&")
print(result) # 输出结果: []
# 转义后可以匹配
result = re.findall(re.escape(".*{m}+^&"), ".*{m}+^&")
print(result) # 输出结果: ['.*{m}+^&']
3.3.8 其他开关参数
语法: 可以在上述所有的方法中, 作为最后一个参数进行传递, 可以修改规则
修饰符 描述 re.I 使匹配对大小写不敏感 re.L 做本地化识别(locale-aware)匹配 re.M 多行匹配,影响 ^和$re.S 使 .匹配包括换行在内的所有字符re.U 根据Unicode字符集解析字符。这个标志影响 \w,\W,\b,\B.re.X 该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解。 1
2
3
4
5
6# 以re.S举例
result = re.search("Hello.World", "Hello\nWorld")
print(result) # 结果将是 None,因为.不匹配换行符
result = re.search("Hello.World", "Hello\nWorld", re.S)
print(result.group()) # <_sre.SRE_Match object; span=(0, 11), match='Hello\nWorld'>
第七节 作业
需求: 爬取小说排行前10页
1 | # ================================= |
第四章 处理json数据 jsonpath包
JsonPath是一种可以快速解析json数据的方式,JsonPath对于JSON来说,相当于XPath对于XML,JsonPath用来解析多层嵌套的json数据。
官网:https://goessner.net/articles/JsonPath/
想要在Python编程语言中使用JsonPath对json数据快速提取,需要安装jsonpath模块
1 | pip install jsonpath -i https://pypi.tuna.tsinghua.edu.cn/simple |
第一节 jsonpath常用语法

代码示例
1 | import jsonpath |
第二节 jsonpath练习
jsonpath对比XPath
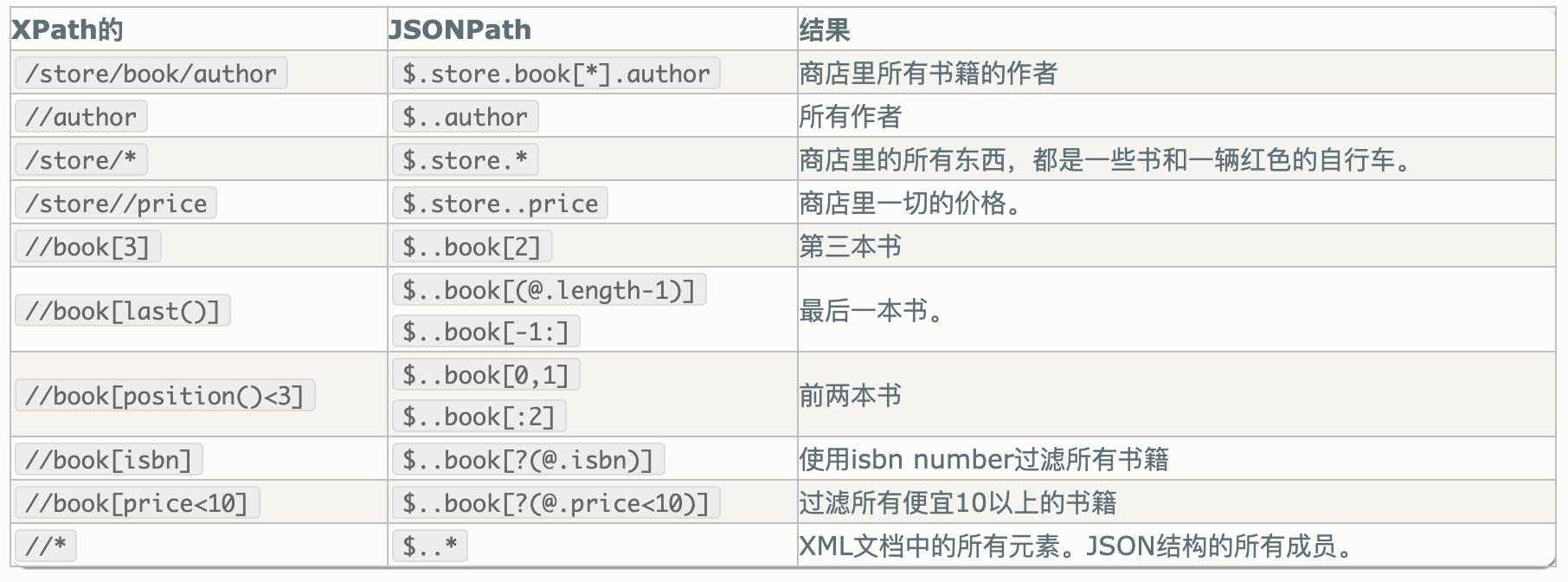
练习代码:
1 | import jsonpath |
- Title: 5.数据提取方式(json,正则)
- Author: 明廷盛
- Created at : 2025-02-15 14:34:49
- Updated at : 2025-02-09 15:55:00
- Link: https://blog.20040424.xyz/2025/02/15/🐍爬虫工程师/第一部分 爬虫基础/5.数据提取方式(json,正则)/
- License: All Rights Reserved © 明廷盛