
5.Redis

Redis学习
第一章 学习Redis的切入点
Redis数据库是什么: ①NoSQL数据库 ②作为缓冲数据库使用 ③支持多种数据结构的存储 ④支持持久化(备份)
第二章Redis的安装(Linux)
第一节 如何安装
第二节 常用命令
- Redis后台启动:
redis-server /root/myredis/redis.conf; 后面是redis.conf文件的路径(可用相对) - 客户端访问:
redis-cli [-p 端口号]; 可以开启多个Redis, 也可以指定访问哪一个端口上的Redis - Redis关闭:
redis-cli [-p 端口号] shutdown - 从Redis客户端返回LInux:
ctrl+c - [Linux] 查询指定redis进程:
ps -ef | grep redis - [Window] 如何进入Redis: ①cd到指定目录打开cmd ②
redis-cli.exe -h 127.0.0.1 -p 6379
第三节 为什么不选择Windows环境
- Redis是单线程工作的, 而Linux有一个特性”多路IO复用”, 从而导致在Linux下的Redis尽管是单线程,效率也很高
第四节 Redis常识和redis.conf
2.4.1 使用哪个dump.rdb和redis.conf文件
- 执行
redis-server [指定的redis.conf]后默认使用的是当前文件夹中的redis.conf和dump.rdb - 建议不要修改原始的redis.conf, 复制一份到新的文件夹, 再做修改
第三章 五大数据类型的存储
第一节 [具体操作](D:\用户\文档\Obsidian Vault\专业学习\Java路线\中间件\Redis学习\常用五大数据类型.xlsx)
第四章 Redis的发布与订阅
第一节 具体操作
第二节 有什么用
第五章 Reids连接IDEA
STEP1: pom.xml 配置
jedis
1
2
3
4
5<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
STEP2: 修改Redis配置文件
- 关闭Linux防火墙:
systemctl stop/disable firewalld.service - 打开redis.conf:
- 注释bind 127.0.0.1(75行)
- 将protected-mode(94行) 的值设置为no
STEP3: 在IDEA中编写测试类
test
1
2
3
4
5
public void test1() {
Jedis redis = new Jedis("192.168.6.100", 6379);
System.out.println(redis.ping()); // 打印PONG则为连接成功
}
STEP4: 图形化界面的Redis操作
填写Linux 地址和端口号即可

第六章 Reids的事务与锁
第一节 事务
6.1.1 如何开启, 执行, 取消事务:
- 语法:
Multi,Exex,discard
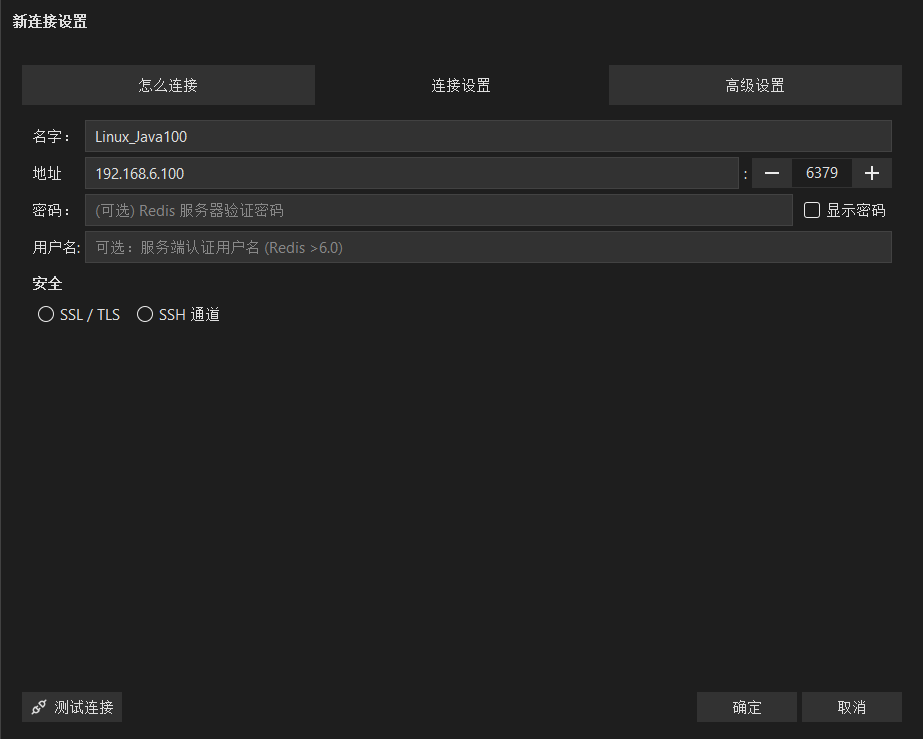
6.1.2 事务出现异常的执行情况
- 组队阶段出现语法错误: 整个队列都会取消(并不是立即, 而是在Exec时取消)
- 执行阶段出现错误: 只有报错的指令不被执行, 其他都会执行, 不会回滚
第二节 锁
6.2.1 锁的分类
悲观锁(MySQL): 顾名思义,就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次在拿数据的时候都会上锁,这样别人想拿这个数据就会block直到它拿到锁。传统的关系型数据库里边就用到了很多这种锁机制,比如行锁,表锁等,读锁,写锁等,都是在做操作之前先上锁。
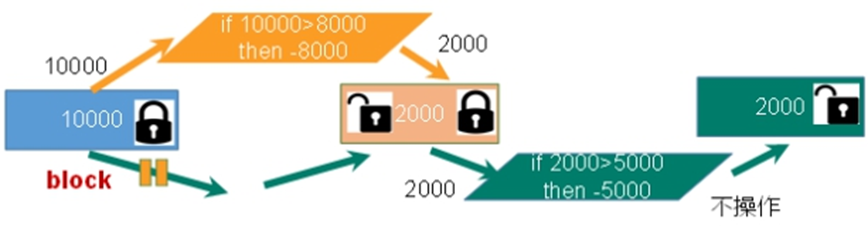
乐观锁(Redis): 顾名思义,就是很乐观,每次去拿数据的时候都认为别人不会修改,所以不会上锁,但是在更新的时候会判断一下在此期间别人有没有去更新这个数据,可以使用版本号等机制。乐观锁适用于多读的应用类型,这样可以提高吞吐量。Redis就是利用这种check-and-set机制实现事务的。
6.2.2 给key上锁🔒
- 语法:
- 给key上锁:
WATCH key [key ...] - 给所有key解锁🔓:
UNWATCH
- 给key上锁:
- 注意⚠️: 如果在执行事务A中, 有任意一个key的版本号对不上(在其他地方被修改), 整个事务将都执行失败并返回空值(nil)
第七章 Redis的持久化(备份)
第一节 RDB(Redis DataBase)
在指定的时间间隔内将内存中的数据集快照写入磁盘, 也就是行话讲的Snapshot快照,它恢复时是将快照文件直接读到内存里
7.1.1 备份的执行过程
- Fork: Fork的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等) 数值都和原进程一致,但是是一个全新的进程,并作为原进程的子进程
- Linux的优势: Linux会采用”写时复制技术”(运行父子进程使用相同的一段物理内存, 只有设计到写入时才会复制进程)
7.1.2 配置文件关于RDB
rdb文件的名称配置: redis.conf[421] 默认为dump.rdb
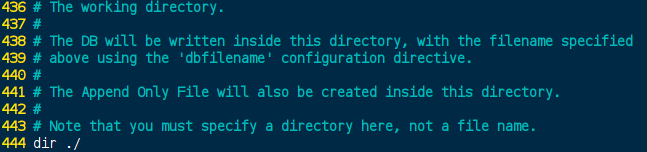
rdb/aof文件的保存路径: redis.conf[444] 默认是当前路径下
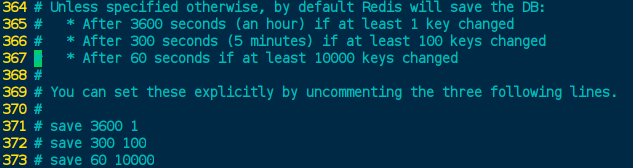
自动保存rdb的策略: redis.conf[371] 默认是不自动保存RDB
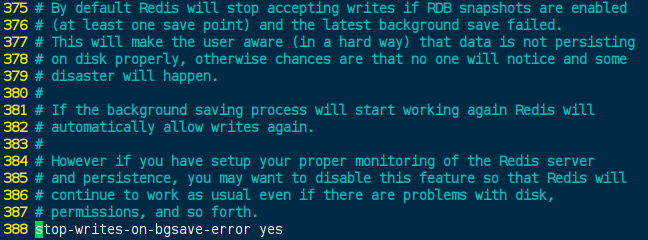
是否关闭Redis的写操作当发生错误时: redis.conf[388] 默认:yes; 推荐yes
是否启用LZF算法对RDB文件进行压缩: redis.conf[394] 默认:yes: 推荐yes
是否检查RDB文件的完整性: redis.conf[403] 默认: yes; 推荐yes



7.1.3 如何触发RDB
- 自动触发: ①改配置文件, 如上 ②shutdown redis的时候
- 手动命令触发:
savebgsave; 区别在于一个前台阻塞保存, 另一个后台异步保存
- 临时停止RDB文件的保存: [Linux]
redis-cli config set save ""; save后给空值,表示禁用保存策略
7.1.4 如何恢复RDB
- 就是.rdb文件的替换; 比如你在这一次打开redis前, 对rdb文件进行保存, 然后后面想回复就替换回来即可
- [Linux]拷贝文件:
cp [-r] source dest:
7.1.5 RDB的优势与劣势
优势: ①适合大规模的数据恢复 ②节省磁盘空间 ③恢复速度快
劣势: ①内存会膨胀2倍 ②”写时拷贝技术”消耗性能 ③意外down掉会丢失最后一次RDB文件后的所有修改
第二节 AOF(Append Only File)
①以日志的形式记录📝每个操作 ②将除读操作外的所有指令写入aof文件 ③只允许追加文件, 不允许修改文件
④如果采用AOF的方式进行持久化, 每次重启redis都会将aof文件的内容从头到尾执行一遍, 以完成数据回复工作
7.2.1 备份的执行过程
- 客户端的请求写命令会被append追加到AOF缓冲区内;
- AOF缓冲区根据AOF持久化策略[always,everysec,no]将操作sync同步到磁盘的AOF文件中;
- AOF文件大小超过重写策略或手动重写时,会对AOF文件rewrite重写,压缩AOF文件容量;
- Redis服务重启时,会重新load加载AOF文件中的写操作,达到数据恢复的目的;
7.2.2 配置文件关于AOF
aof文件的名称配置: redis.conf[1234] 默认为appendonly.aof
aof文件的保存路径,同rdb的路径一致
是否开启aof备份机制: reids.conf[1230] 默认:no
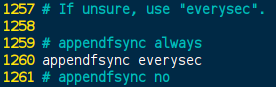
AOF同步频率设置: redis.conf[1260] 默认:everysec


7.2.3 如何触发AOF
appendfsync always: 始终同步,每次Redis的写入都会立刻记入日志;性能较差但数据完整性比较好appendfsync everysec: 每秒同步,每秒记入日志一次,如果宕机,本秒的数据可能丢失。appendfsync no: redis不主动进行同步,把同步时机交给操作系统。
7.2.4 如何恢复AOF
- 本质上还是文件, 同rdb一样处理
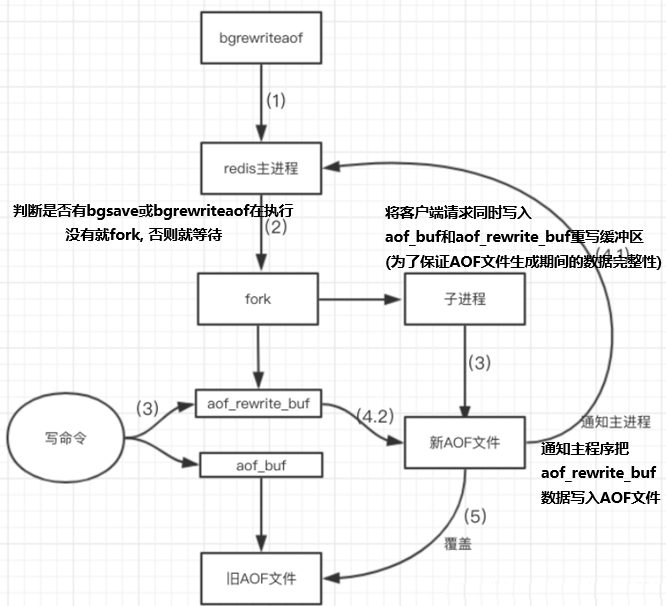
7.2.5 AOF的Rewrite压缩机制
语法:
bgrewriteaof作用: 只保留可以恢复数据的最小指令集
底层实现: AOF文件持续增长而过大时,会fork出一条新进程来将文件重写(也是先写临时文件最后再rename),redis4.0版本后的重写,就是把rdb 的快照,以二级制的形式附在新的aof头部,作为已有的历史数据,替换掉原来的流水账操作。
7.2.6 AOF的优势与劣势
- 优势: ①备份机制更稳健,丢失数据概率更低。②可读的日志文本,通过操作AOF文件,可以处理误操作。
- 劣势: ①比RDB占用更多的磁盘空间 ②恢复备份速度要慢 ③每次读写都同步的话,有一定的性能压力
第三节 RDB🆚AOF
①官方推荐两个都启用。②如果对数据不敏感,可以选单独用RDB。③不建议单独用 AOF,因为可能会出现Bug。
④如果只是做纯内存缓存,可以都不用。
第八章 Redis的主从复制
主从复制的作用: ①读写分离, 性能拓展(主-写, 从-读) ②容灾快速恢复(从down时, 其他从任然可用)
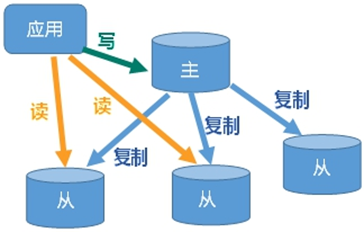
第一节 如何实现主从复制
有一个初始的端口为6379的redis(主)
在文件夹中, 创建端口为6380和6381的redis(从) [一个config就是一个redis]
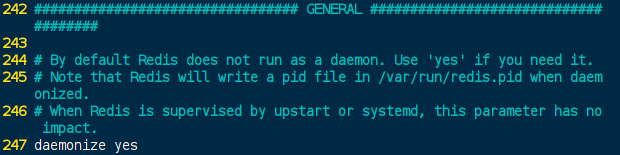
将原始redis的主从复制打开 redis.conf[247] daemonize 默认no;
对6379,6380,6381的confi进行编写:
- 注意⚠️: 因为每个redis不能读一样的rdb文件, 所以需要改写rdb文件的名称(如果要开启aof的话, aof的名称也得改写)
1
2
3
4
5
6
7
8# 包含原始配置文件的所有内容
include /root/myredis/redis.conf
# Pid文件名字pidfiles
pidfile /var/run/redis_6379.pid
# 端口改写
port 6379
# rdb文件改写
dbfilename dump6379.rdb启动指定的conf文件, 以运行不同的redis
- 开启不同的redis:
redis-server redis6380.conf - 进入不同的客户端:
redis-cli -p 6380
- 开启不同的redis:
常用命令:
- 认主:
slaveof <ip> <port> - 查看当前服务器主仆状态:
info replication
- 认主:

第二节 主从复制的一些性质
8.2.2 主仆机的复制原理
Slave启动成功连接到master后会发送一个sync命令给到master
Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
全量复制(首次复制):而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
增量复制(再次复制):Master继续将新的所有收集到的修改命令依次传给slave,完成同步
8.2.1 主仆机的性质
- 主机
- 可以写, 可以读
- 主机挂掉, 重启就行,一切如初(该有的小弟还有)
- 从机
- 只能读, 不能写
- 扑挂掉后, 重启会消失仆的身份; 但再次认主, 会重新拷贝最新的数据
8.2.3 薪火相传
- 定义: 上一个slave可以是下一个slave的Master
- 意外情况: 风险是一旦某个slave宕机,消息传递中断, 后面的slave都没法备份
8.2.4 反客为主
- 定义: 当一个master宕机后,后面的slave==通过命令==可以立刻升为master,其后面的slave不用做任何修改。
- 语法: 将从机变成主机:
slaveof no one
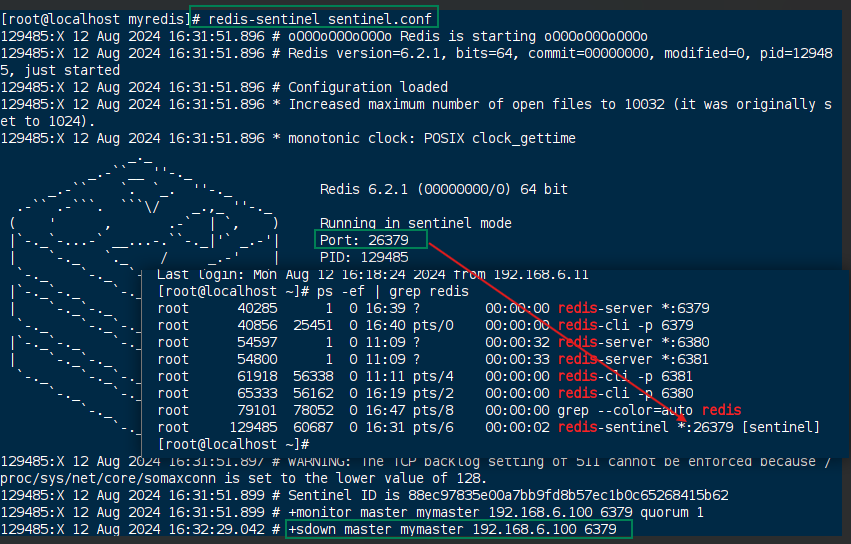
第三节 哨兵模式(Sentinel)
8.3.1 如何实现哨兵模式
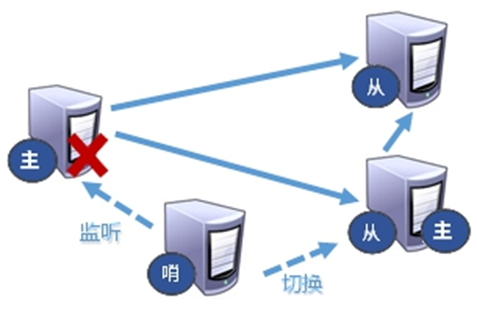
定义: 反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库
- 反客为主的自动版本: 无需通过命令
- 投票数: 至少有几个哨兵认为主节点不可用, 才启动主机切换
实现步骤:
调整为一主二从的模式
自定义的/root/myredis目录下新建sentinel.conf文件 (名字不能错)
配置哨兵,填写内容
sentinel monitor:这是一个 Sentinel 监控指令,用于告诉 Sentinel 需要监控一个特定的 Redis 主节点。mymaster:这是为 Redis 主节点定义的名称,用于在 Sentinel 配置中标识这个主节点。在配置中提到的所有与mymaster相关的设置都是针对这个主节点的。192.168.6.100:这是 Redis 主节点的 IP 地址,Sentinel 将会监控这个地址上的 Redis 服务。6379:这是 Redis 主节点的端口号,Sentinel 将会连接到这个端口来监控 Redis 主节点的状态。1:这是quorum的值,表示在触发故障转移之前,需要至少有多少个 Sentinel 实例认为主节点不可用(下线)。在这个例子中,只要有 1 个 Sentinel 认为主节点下线,就会触发故障转移
1
sentinel monitor mymaster 192.168.6.100 6379 1
前台启动哨兵, 查看效果
- 执行:
redis-sentinel /root/myredis/sentinel.conf
- 执行:
注意⚠️:
当主服务器再次上线时, 不会没有身份, 会变成从服务器
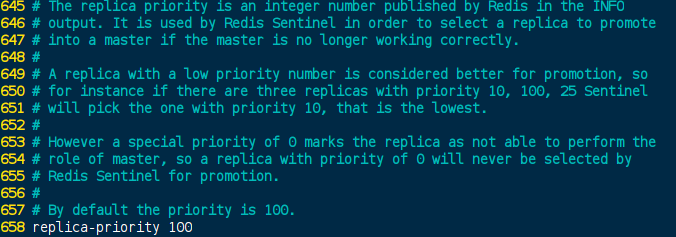
可以在配置文件夹中, 设置`replica-priority的值(值越小, 越优先)
这个故障切换时有延迟的, 哨兵检测需要时间, 复制数据需要时间
故障修复的整体过程

第四节 Java与主从复制
- 原理: 哨兵模式也是一个redis, 所以连接哨兵模式的端口号即可
1 | package com.mts.utils; |
第九章 Redis集群(Cluster)
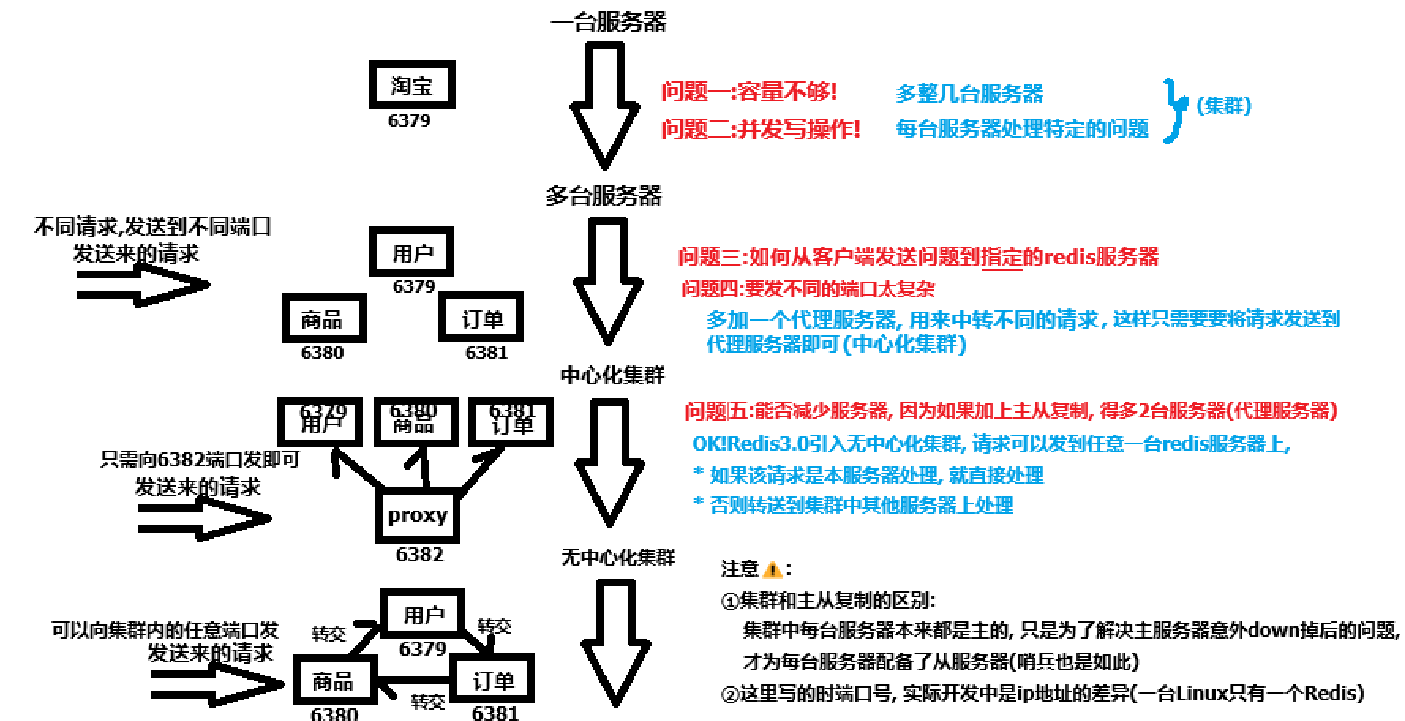
第一节 如何实现集群
将rdb,aof文件都删除掉
创建6个实例名字为”redis6379.conf”, 并填写以下内容
- cluster-node-timeout 1500: ①单位为ms ②如果主节点失联超过15000ms, 自动进行主从切换
1 | include /root/myredis/redis.conf |
- 启动6个redis
- 合体(成为去中心化集群)
- 插槽: 每个插槽上可以存数据, 每个写的指令会到写到不同的插槽上, 合体之后, 你只管写, redis会帮你转到对应的插槽
1 | redis-cli --cluster create --cluster-replicas 1 192.168.6.100:6379 192.168.6.100:6380 192.168.6.100:6381 192.168.6.100:6389 192.168.6.100:6390 192.168.6.100:6391 |
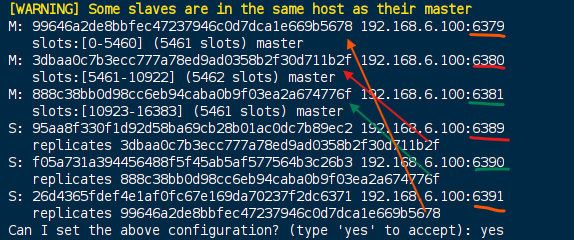
- 使用集群的命令, 进入去中心化集群
- 语法:
redis-cli -c -p 6379
第二节 集群相关操作
9.2.1 关于redis cluster
- 一个集群至少有三个主节点
- 分配原则尽量保证每个主数据库运行在不同的IP地址,每个从库和主库不在一个IP地址上。
9.2.2 关于slots
- 一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个键都属于这 16384 个插槽的其中一个,
- 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽, 其中 CRC16(key) 语句用于计算键 key 的 CRC16 校验和 。
- 一个插槽可以有多个key
9.2.3 在集群中录入值
- 不在一个slot下的键值,是不能使用mget,mset等多键操作。

- 可以通过**{}**来定义组的概念,从而使key中{}内相同内容的键值对放到一个slot中去(查的时候也要带{})

9.2.4 查询集群中的值
计算key应该保存在那个插槽:
cluster keyslot key计算某个插槽中保存的key的数量:
cluster countkeysinslot slot的值返回 count 个 slot 槽中的键:
cluster getkeysinslot <slot> <count>
第三节 故障恢复
9.3.1 其中一台主机down
==> 切换他的从机(自动配置了哨兵模式, 无需我们自己多写一个哨兵)
9.3.2 down掉的主机恢复
==> 变为从机
9.3.3 某一个节点的主从全部down
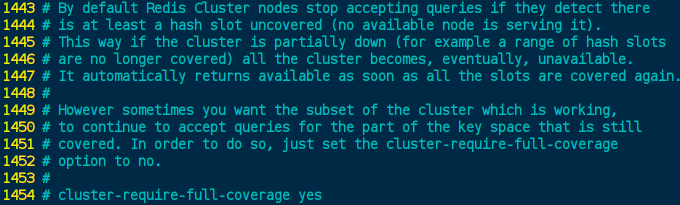
cluster-require-full-coverage 为yes==>整个集群都挂掉cluster-require-full-coverage 为no==>该插槽数据全都不能使用,也无法存储, 其他节点正常
redis.conf [1454] cluster-require-full-coverage 默认: 注释掉
第四章 Java与集群
1 | Set<HostAndPort> set =new HashSet<HostAndPort>(); |
- Title: 5.Redis
- Author: 明廷盛
- Created at : 2025-02-15 22:01:26
- Updated at : 2025-02-17 16:22:00
- Link: https://blog.20040424.xyz/2025/02/15/😼Java全栈工程师/第四部分 中间件/5.Redis/
- License: All Rights Reserved © 明廷盛