4.Requests模块

第一章 Requests基本方法
第一节 requests常用能发送请求的
- 请求: get()/post()/…
| 序号 | 类型 | 如何获取 | 区别 |
|---|---|---|---|
| ① | requests模块 |
import requests |
最普通的 |
| ② | <requests.sessions.Session> |
session = requests.session() |
携带服务器发来的cookie信息, 进行请求 |
第二节 常见返回值处理
| 序号 | 常用方法 | 作用 | 什么时候用 |
|---|---|---|---|
| ① | result .text |
返回以文本格式(HTML代码) | 页面的HTML代码 |
| ==②== | result .content |
返回以二进制格式 | 页面只有,图片,音频,视频 |
| ③ | result .json() |
返回以json格式 | 页面只有JSON数据 |
| ④ | result .status_code |
返回此次请求服务器返回的状态码 | |
| ==⑤== | result .headers |
获取**响应头** | |
| ==⑥== | result .request.hearders |
获取该次请求的**请求头** | request的头部,有cookie |
| ⑦ | result .cookies |
获取cookies | 可以强转为字典 |
| ⑧ | result.content.decode(“指定编码”) | 先返回二进制, 然后自定义解码获取html源码 | 页面的HTML代码 |
第三节 python的解码和编码
| 方法 | 作用 |
|---|---|
| byte类型数据.encode(“编码格式”) | 将二进制数据**编码为**指定编码格式 |
| byte类型数据.decode(“编码格式”) | 将二进制数据**解码为**指定编码格式 |
第二章 自定义请求头参数的请求headers
第一节 为什么要设置请求头
- 原因: 当我们使用requests模块进行页面请求时, 其中
User-Agent: python-requests/2.18.4这是默认的User-Agent的请求, 那不就等于告诉百度, 我是爬虫了, 肯定不行 - 如何获取发送请求的请求头???: 见⑥
第二节 如何设置请求头
- 语法:
.get(..., headers=my_hearder): 其中my_hearder是字典类型
aim_url = "https://www.baidu.com/"
my_header = { # 1.设置请求头
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(aim_url, headers=my_header) # 2.get方法中传入请求头
print(response.content.decode())
第三章 发送GET请求get() params
需求: 在发送请求的同时, 携带”请求参数”
第一节 方式一: 问号拼接
- 语法: 问号拼接, 不多说了; 回顾一点GET是默认的是拼接在地址栏的(flask框架)
aim_url = "https://www.baidu.com/s?word=python"
response = requests.get(aim_url, headers=my_header)
print(response.content.decode())
第二节 ==方式二==: 指定get()的params参数
- 语法:
.get(..., params=my_params): 其中my_params是字典类型; 等同于在末尾拼接问号
aim_url = "https://www.baidu.com/s"
my_params = {
"word": "python"
}
response = requests.get(aim_url, headers=my_header, params=my_params) # 1.指定参数
print(response.content.decode())
第四章 发送POST请求post() data
需求: 爬取巨潮资讯网页面中的主体信息内容 (这个网站比较松, data,params都能爬,
但请注意params与get()请求连用(拼接地址栏); data与post()请求连用(表单隐藏发送)
第一节 整体流程
4.1.1 整体流程
- 用户点击”下一页”的按钮
- 前端ajax向指定后端服务器URL发送”下一页请求”POST
- 后端服务器根据URL地址,调用对应的方法
- 后端将从数据库查询好的数据, 返回给ajax,以JSON的格式
- 前端ajax对请求进行处理, 并展示在页面上
4.1.2 流程关键点
- 后端服务器URL是什么? 知道了这个,我们requests模拟发送即可
- 需要携带什么参数? 只有携带对应的参数, 方法才能响应,否则容易403
第二节 如何找两个关键点
4.2.1 如何找后端服务器URL
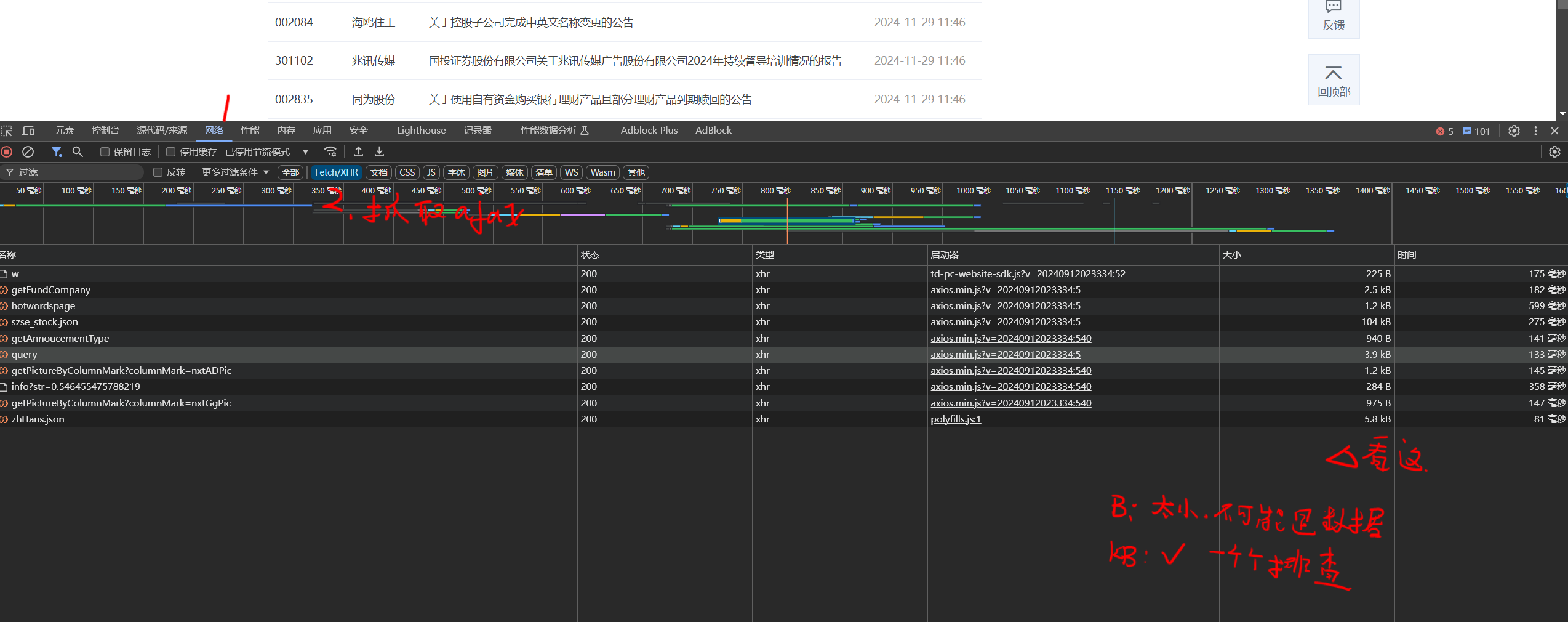
4.2.2 需要携带什么参数
我们自己写前后端的时候, 是不是要提交一个表单给后端, 所以我们的目标就是**模拟提交一样的字段**
第三节 发送POST请求post()使用 data传参
4.3.1 GET和POST的区别
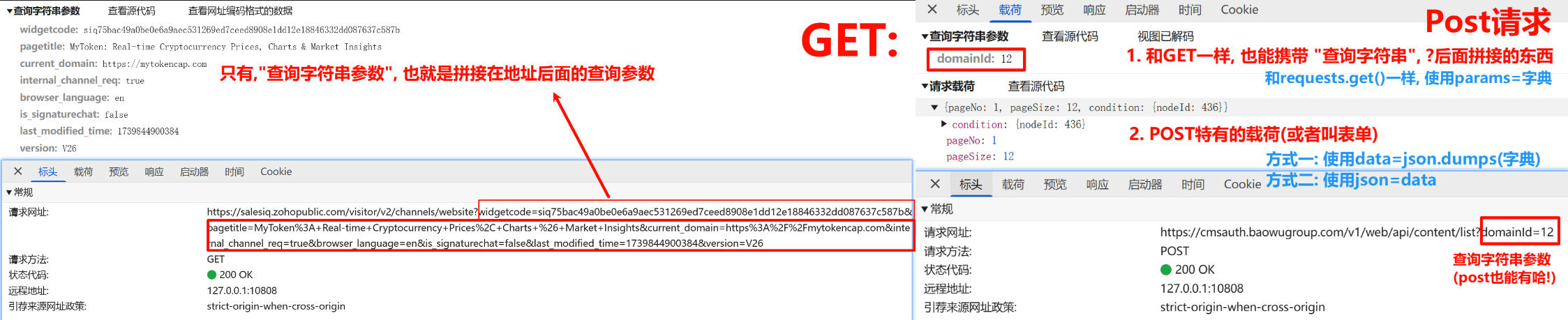
- & 语法:
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36",
}
url = "https://cmsauth.baowugroup.com/v1/web/api/content/list"
# "查询字符串参数
params = {
"domainId": "12"
}
# "请求载荷"
data = {
"pageNo": 3,
"pageSize": 12,
"condition": {
"nodeId": 436
}
}
# 像这里, 就采用的json=字典进行传参
response = requests.post(url, headers=headers, params=params, json=data, verify=False)
print(response.text)
print(response)
4.3.2 两种传载荷方式data= VS json=
| 特性 | data= | json= |
|---|---|---|
| 数据类型(python) | str | dict |
| 序列化方式 | 需手动json.dumps() | requests自动帮你json.dumps() |
| Content-Type | 默认application/x-www-form-urlencoded | 自动设置为application/json |
| 文件上传 | 支持(需特殊格式) | 不支持 |
- $ 语法: 如下两种方式是一样的
- ! 注意: 无论, 用哪个, 本质上都会json.dumps()以下, 区别只是一个手动, 一个自动
data = {
"pageNo": 3,
"pageSize": 12,
"condition": {
"nodeId": 436
}
}
response = requests.post(url, headers=headers, params=params, data=json.dumps(data), verify=False) # 使用 data=
response = requests.post(url, headers=headers, params=params, json=data, verify=False) # 使用 json=
第五章 使用IP代理发送请求proxies
因为同一个IP一直访问, 会被封, 所以得需要代理IP来访问, 下面将**如何使用代理IP发送请求**
需求: 分别使用代理和不使用代理,获取IP查询网站所返回的数据
第一节 如何设置代理
- 语法:
get(proxies=my_proxies): my_proxies是字典类型&&必须为{代理协议:端口} - 代理的协议: ①http ②https ③socket
aim_url = "https://httpbin.org/ip"
my_proxies = { # 1.代理是字典
"http": "http://127.0.0.1:10808"
}
response = requests.get(aim_url, proxies=my_proxies) # 2.设置代理数据
print(response.json())
第六章 发送携带Cookie的请求cookies
需求: 发送请求的时候携带 cookies
需求: 在CSDN的个人信息页面获取个人头像的图片
第一节 ==方式一==: 在headers中设置
- 语法:
headers传递的字典中设置键值Cookie
import requests
aim_url = "https://msg.csdn.net/v1/web/message/view/unread" # CSDN的个人信息页面
# 请求头中携带cookies
my_header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
"Cookie": "太长了, 自己去抓包复制"
}
response = requests.post(aim_url, headers=my_header) # 1.注意是请求头
print(response.json())
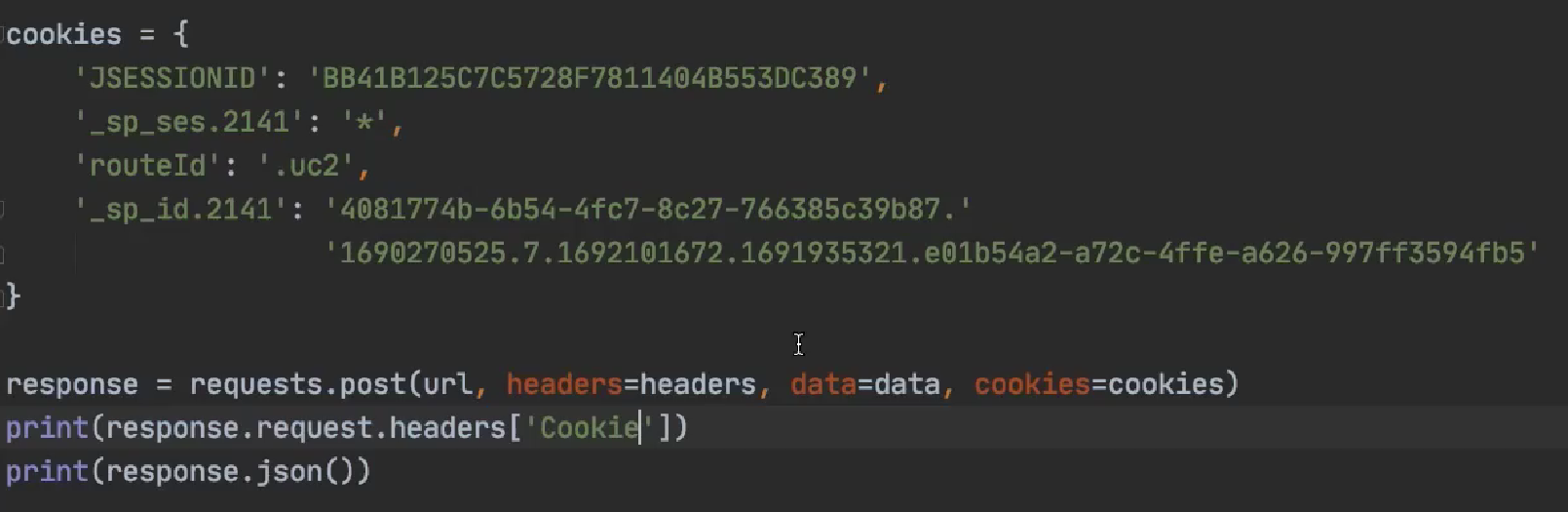
第二节 方式二: 单独设置cookies
- 语法:
get(cookies=my_cookies):去把每个cookie分开, 写成键值对的形式, 太多了不推荐这种方式
第七章 关于Session session.请求()
第一节 浏览器状态记录 基础知识回归
- ①会话指的是这个标签的关闭, 不是整个浏览器关闭, 重新访问这个网站就已经是第二个会话了, 但重新roll这个网站还是当前会话
- ②Cookie是保存在浏览器端的, Session是保存在服务器端的(但浏览器端要用Cookie保存session_id)
- ③Cookie的有效时间是在new Cookie()出来对象的时候设置的(-1永久,0失效,>0s), 这个时间将带着到浏览器储存
- ④Session的有效时间是同一的, 通过request.getSession()获取到session后, session.setMaxIntervi() (s为单位, 30min默认)
第二节 爬虫涉及到的相关知识
- ①只有请求头中才有Cookie;
- ②请求头中没有Session; Session是服务器端的, 浏览器端只以一个cookie的形式保存一个Session_id,来和服务器取得认可
- ③请求Cookie表示的是: 浏览器发送给服务器的cookie(可能是userinfo,后续的session_id..)
- ④响应Cookie表示的是: 服务器发送给浏览器的Cookie(可能是首次访问, 要服务器制作好的session_id发给浏览器)
==第三节 使用session请求的特殊之处==
- 类型:
<class 'requests.sessions.Session'> - 获取:
session = requests.session() - 特殊之处: 携带服务器发来的cookie信息, 进行请求
- 下面这个例子: 先是通过访问官网获取到了SESSIONID, 这样一来使用这个SESSIONID就可以访问一次后端API, 每次访问后端API前都会先访问官网地址, 等同与拿到一个一次性的KEY;
index_url = "http://www.cninfo.com.cn/new/index" # 官网地址
api_url = "http://www.cninfo.com.cn/new/disclosure" # 爬取数据的接口
# 1.获取session对象
session = requests.session()
res = session.get(index_url) # 一. 通过它向官网发送一次数据,session会保存,服务器传来来的cookie(也就是SESSIONID)
session_id = res.cookies.get("JSESSIONID")
"""...中间代码有省略""""
# 2.发送请求
result = session.post(api_url) # 二. 后续使用session发请求时,都会更新这个cookie信息(如果变动的话),并携带发送其他请求
print(result.cookies)
第四节 什么时候会用到session
需求: 假设这个如下网站符合 一个SESSIONID只能使用进行一次后端接口的调用;(当然这个网站很松,但SESSIONID每次都在变,但一个可以用好多次🤣)
index_url = "http://www.cninfo.com.cn/new/index" # 官网地址
api_url = "http://www.cninfo.com.cn/new/disclosure" # 爬取数据的接口
# 1.获取session对象
session = requests.session()
res = session.get(index_url)
session_id = res.cookies.get("JSESSIONID") # 就是session_id,每个网站的开发人员的命名习惯不同
# 2.发送请求(有些网站可能因为session_id是动态的,每次都要校验,一直发同一个是无法得到数据的,只是这个网站比较松)
my_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
}
my_data = {
"column": "szse_latest",
"pageNum": "3",
"pageSize": "30",
"sortName": "",
"sortType": "",
"clusterFlag": "true",
}
result = session.post(api_url, headers=my_headers, data=my_data) #这里发送请求的时候, 就会带上cookie(session_id)
if result.status_code == 200:
print(result.json())
else:
print(result.status_code)
第八章 证书忽略 verify
第一节 简单的证书错误
需求: 爬取这个网站的主页面内容(当然这个网站崩了, 但错误警告还是在的)
- 语法:
result = requests.get(aim_url,verify=False)请求的时候加上这个verify=False即可 - 错误类型:
requests.exceptions.SSLError如果存在证书错误警告, 会报这个错 - 其他: 出现如下报错, 正常, 安全警告而已
InsecureRequestWarning: Unverified HTTPS request is being made. Adding certificate verification is strongly advised.
aim_url = "https://yjcclm.com/"
try:
result = requests.get(aim_url)
except requests.exceptions.SSLError as e:
result = requests.get(aim_url,verify=False) # 1.请求时指定verify变量为False
print(result.content.decode())
第二节 dh key too small
原解决地址:link
STEP1: urllib3降级
- & 说明: 如果出现
execjs用不了, 就继续降, 降到1.24.3
pip install urllib3==1.25.6
STEP2: 完全让urllib3忽略那些安全问题
import requests
import urllib3
requests.packages.urllib3.disable_warnings()
requests.packages.urllib3.util.ssl_.DEFAULT_CIPHERS += ':HIGH:!DH:!aNULL'
try:
requests.packages.urllib3.contrib.pyopenssl.util.ssl_.DEFAULT_CIPHERS += ':HIGH:!DH:!aNULL'
except AttributeError:
# no pyopenssl support used / needed / available
pass
page = requests.get(url, verify=False)
第九章 请求重试@retrying.retry()
需求: 如果网页的返回的状态码不是200, ①就重试3次访问, 如果还是不行, 抛出异常 ②否则打印网页内容
- 语法:
@retrying.retry(stop_max_attempt_number=重试次数n): retrying包需要自己下 - 作用: 对该方法重试n次, 如果还是抛异常,就直接抛出, 其中只要有一次成功(没有抛出异常)就继续执行
import requests
import retrying
def get_access(url):
print("重新连接....")
result = requests.get(url)
assert result.status_code == 200, "状态码不正确" # ps:这里每打印是因为上面因为证书的问题,提前报错了
return result
if __name__ == '__main__':
aim_url = "https://yjcclm.com/"
result = get_access(aim_url) # 一. 这里如果返回不是200, 就报错
print(result.content.decode()) # 二. 否则打印网页内容
第十章 作业
需求: 爬取 百度图片 封装一个方法, ①传入搜索关键字key_word ②保存n页的图片 ③将抓取的图片保存在./image/中
# =================================
# @Time : 2024年11月30日
# @Author : 明廷盛
# @File : 14.作业(爬取百度图片).py
# @Software: PyCharm
# @ProjectBackground: 15min内爬取 [百度图片](https://image.baidu.com/) 封装一个方法, ①传入搜索关键字key_word ②将抓取的图片保存在./image/中 (不用管照片数量)
# =================================
import requests
import uuid
def get_baidu_image(key_word, num=30):
aim_url = "https://image.baidu.com/search/acjson";
header = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36",
}
params = { # GET请求, 用params
"tn": "resultjson_com",
"logid": "7424101381001970871",
"ipn": "rj",
"ct": "201326592",
"is": "",
"fp": "result",
"fr": "",
"word": key_word, # 这个主要控制 搜索内容(下面不是)
"queryWord": key_word,
"cl": "2",
"lm": "",
"ie": "utf-8",
"oe": "utf-8",
"adpicid": "",
"st": "-1",
"z": "",
"ic": "0",
"hd": "",
"latest": "",
"copyright": "",
"s": "",
"se": "",
"tab": "",
"width": "",
"height": "",
"face": "0",
"istype": "2",
"qc": "",
"nc": "1",
"expermode": "",
"nojc": "",
"isAsync": "",
"pn": 2, # 第几页
"rn": 60, # 每页的图片数量(经测试每页最多60张图片)
"gsm": "1e",
"1732933641118": "",
}
result = requests.get(aim_url, headers=header, params=params)
# 处理数据
json_result = dict(result.json())
print(len(json_result.get("data")))
index=1
for i in json_result.get("data"):
pic_url = i.get("thumbURL")
if pic_url is not None:
print(str(index) + ": " + pic_url)
index += 1
download_and_save_pic(pic_url)
def download_and_save_pic(pic_url):
result = requests.get(pic_url)
image_b = result.content # 图片的二进制文件
with open("./image/" + str(uuid.uuid1()) + ".png", "wb") as f:
f.write(image_b)
if __name__ == '__main__':
get_baidu_image("原神", 1)
- Title: 4.Requests模块
- Author: 明廷盛
- Created at : 2026-02-02 05:32:25
- Updated at : 2025-02-09 15:54:00
- Link: https://blog.20040424.xyz/2026/02/02/🐍爬虫工程师/第一部分 爬虫基础/4.Requests模块/
- License: All Rights Reserved © 明廷盛