2.需要用到的python基础知识

python全版本安装: https://www.python.org/downloads/windows/
一. 断言assert
语法:
assert condition,statement作用: ①如果condition为True继续执行下面代码 ②否则执行Statement语句,中断(不继续执行下面语法)并抛出
AssertionError错误assert 10 > 11, "错误" # 如果条件为假 抛出assert 10 > 11, "错误"\n AssertionError: 错误
print("正确") # 如果条件为真 继续执行
二. 文件的读写 with open() as f
语法:
with open("文件路径","读取方式") as f读取方式:
模式 描述 'r'读取模式。这是默认的模式。如果文件不存在,抛出 FileNotFoundError。'w'写入模式。如果文件存在,会被覆盖。如果文件不存在,创建新文件。 'a'追加模式。如果文件存在,写入的数据会被追加到文件末尾。如果文件不存在,创建新文件。 'b'二进制模式。可以和 'r'、'w'、'a'组合使用,例如'rb'、'wb'、'ab'。't'文本模式。这是默认的模式,可以和 'r'、'w'、'a'组合使用,例如'rt'、'wt'、'at'。'+'更新模式。可以和 'r'、'w'、'a'组合使用,例如'r+'、'w+'、'a+'。允许读写文件。组合模式 描述 'rb'读取模式,二进制格式。 'wb'写入模式,二进制格式。如果文件存在,会被覆盖。如果文件不存在,创建新文件。 'ab'追加模式,二进制格式。如果文件存在,写入的数据会被追加到文件末尾。如果文件不存在,创建新文件。 'rt'读取模式,文本格式。 'wt'写入模式,文本格式。如果文件存在,会被覆盖。如果文件不存在,创建新文件。 'at'追加模式,文本格式。如果文件存在,写入的数据会被追加到文件末尾。如果文件不存在,创建新文件。 'r+'读取和写入模式。如果文件不存在,抛出 FileNotFoundError。'w+'读取和写入模式。如果文件存在,会被覆盖。如果文件不存在,创建新文件。 'a+'读取和追加模式。如果文件存在,写入的数据会被追加到文件末尾。如果文件不存在,创建新文件。 image = response.data # 一.image为二进制数据
with open("2.png", "wb") as f: # 二. f可以为需要操作文件的变量名称
f.write(image) # 三. 进行写入
三. 字符和ASCII的转化ord() chr()
语法: ①字符转ASCII
ord(字符)②ASCII转字符chr(字符)助记: 记转字符chr就好了(char字符)
四. 字符串字面量前缀r b u f
语法:
r"字符串内容"作用: 字符串前面加上字母
r表示这是一个原始字符串(raw string)。原始字符串中的所有转义字符都不生效说明: ①比如str=”\n”; len(str)=1 ② 但str=r”\n”; len(str)=2
举例:
str len(str) 解释 r”\\“ 2 原始字符串中的所有转义字符都不生效 “\n” 1 不是原始字符串, \n为转义字符,长度为1“\\n” 2 不是原始字符串,”\\“转义为”\“, n单独一个 r”\\n” 3 原始字符串中的所有转义字符都不生效 其他转义字符:
字符串字面量前缀 作用 说明 r原始字符串(不解析转义字符) b字符串中的内容为二进制 音乐,视频,图片 uUnicode字符串 中文 f格式化输出字符串 f"username:{name}"
五. 转义字符 \\ \n …
重点: 所有的转义字符长度都是1
理解:
疑问: “\\n”和”\n”的区别:
在字符串中
\n是换行的转义, 用来输出回车。
\\\n 前面两个\是一体的, 为转义字符\。 后面的n是独立的。
也就是会输出\n这样的两个字符,而不是一个换行。

六. 携带索引的迭代 enumerate()
语法:
enumerate(迭代对象)作用: 这样包装的迭代对象, 会返回index和原迭代对象的内容(可能不只一个)
# ① 一个 原迭代对象的内容
for index, j in enumerate(my_str):
print(f"{index}: {j}")
# ② 多个 原迭代对象的内容
my_dict = {"name": "Tom", "age": "10"}
for index, (key, value) in enumerate(my_dict.items()):
print(f"{index}: <{key},{value}>")
七. 函数传递无限参数*args
- 这个参数名任意(不一定是
*args) - args这个变量会自动将传递来的无限参数封装为元组类型
- 必须作为函数的最后一个参数
def my_execute(sql, *args):
print(f"参数: {args}, 类型: {type(args)}")
if __name__ == '__main__':
my_execute("sql", 1, "3423", 5.53, "0f0dsfs", True)
# 参数: (1, '3423', 5.53, '0f0dsfs', True), 类型: <class 'tuple'>
八. python生成器
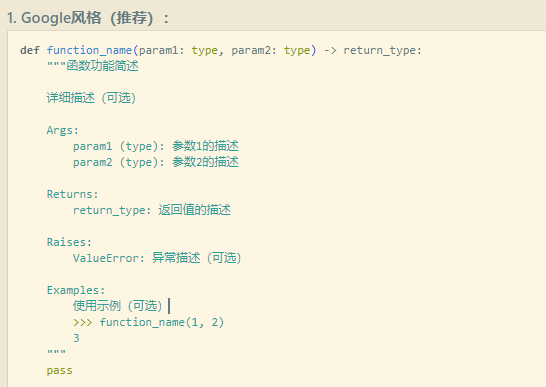
九. python方法注释(Google风格)
十. 协程 asyncio
视频 [[课堂笔记]] 主要去看!笔记和视频, 这里只是介绍如何安装aiohttp
用python310的版本, 和阿里云的镜像; cd到指定310python.exe目录执行
python.exe -m pip install aiohttp -i https://mirrors.aliyun.com/pypi/simple
- 概念: 协程(Coroutine) ,也可以被称为微线程,是一种用户态内的上下文切换技术。简而言之,其实就是通过一个线程实现代码块相互切换执行。
- 任务列表 和 多个任务如何执行
import asyncio
async def func():
print("1")
await asyncio.sleep(2) # 使用 asyncio 的 sleep
print("2")
async def func2():
print("3")
await asyncio.sleep(2) # 使用 asyncio 的 sleep
print("4")
if __name__ == '__main__':
loop = asyncio.get_event_loop() # 获取事件循环
tasks = [func(), func2()] # 创建任务列表
loop.run_until_complete(asyncio.gather(*tasks)) # 使用 gather 来运行所有任务
# 语法: * 操作符用于函数调用时,表示将一个可迭代对象(如列表、元组等)展开为函数的位置参数。
loop.close() # 关闭事件循环
十一. Python环境
第一节 miniconda与Pycharm
11.1.1 miniconda的安装和Pycharm联动
- miniconda安装: https://blog.csdn.net/AlgoZZi/article/details/145074821
- & 说明: 安装好后 ①将miniconda下的condabin加到电脑环境中 ②conda源没必要去配, 速度差不多(但是pip源需要去配)
- Pycharm配置miniconda: https://www.bilibili.com/video/BV1eY411F75R/?spm_id_from=333.824.header_right.history_list.click
- & 说明: 选D:/miniconda/envs下你创建环境中的python.exe; 注意每创建一个python项目都要选对于的环境
11.1.2 关于conda换源
- ! 有时候conda创建环境失败
HTTPError等错误, 就得考虑conda换源了
STEP1: 清除所有缓存+确保无环境激活
conda clean --all -y
conda deactivate
STEP2: 创建.condarc文件 (conda配置文件)
- $ 位置:
.condarc这个文件一般放在C:\Users\15943\.condarc这个目录下
channels:
- defaults
show_channel_urls: true
default_channels:
- https://mirrors.ustc.edu.cn/anaconda/pkgs/main
- https://mirrors.ustc.edu.cn/anaconda/pkgs/r
- https://mirrors.ustc.edu.cn/anaconda/pkgs/msys2
custom_channels:
conda-forge: https://mirrors.ustc.edu.cn/anaconda/cloud
pytorch: https://mirrors.ustc.edu.cn/anaconda/cloud
STEP3: conda使用配置文件
- $ 语法: 后面是你
miniconda3\envs\的路径, 写你自己的 - $ 语法:【查】可以通过
conda info查看
conda config --add envs_dirs D:\miniconda3\envs
conda info
第二节 下载源
1.1.1持久换源和临时换源
python -m pip config list
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple
pip install xxxxx -i 镜像地址
第三节 包
1.2.1 【查】查看环境中的包
1.2.2 下载包
| 常用 | 命令 | 功能描述 |
|---|---|---|
| ❗ | pip install <package> |
安装指定的 Python 包 |
| ❗ | pip install <package>==<version> |
安装指定版本的 Python 包 |
| ❗ | pip install <package> -U 或 pip install --upgrade <package> |
升级指定的 Python 包到最新版本 |
| ❗ | pip install -r requirements.txt |
根据 requirements.txt 文件批量安装依赖包 |
| ❗ | pip uninstall <package> |
卸载指定的 Python 包 |
| ❗ | pip show <package> |
显示指定包的详细信息,如版本、依赖等 |
| ❗ | pip list |
列出当前环境中已安装的所有 Python 包及其版本 |
pip list --outdated |
列出当前环境中所有可升级的包 | |
pip freeze |
以 requirements.txt 格式输出当前环境中已安装的包及其版本,常用于生成依赖文件 |
|
pip search <query> |
在 PyPI 上搜索包含指定关键词的包(注:该命令在较新版本的 pip 中可能不可用) | |
pip install --user <package> |
以用户模式安装包,不需管理员权限,安装到用户目录 | |
pip install --target=<dir> <package> |
将包安装到指定目录 | |
pip install --no-deps <package> |
安装包时忽略其依赖 | |
pip install --editable <path_or_url> |
以可编辑模式安装本地或远程的包,便于开发调试 |
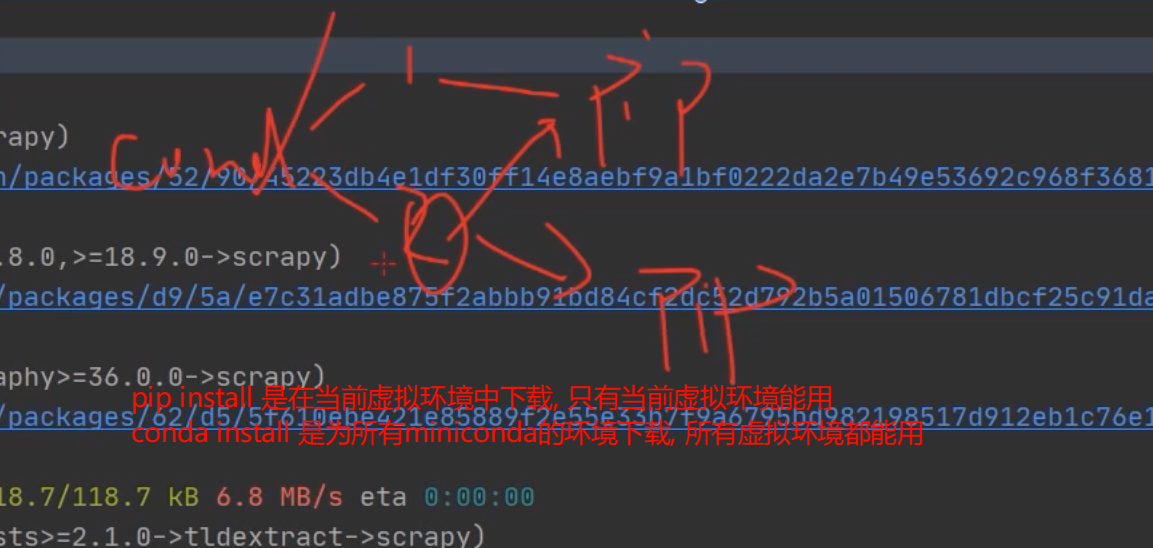
1.2.2 pip和conda下载的区别
第四节 python环境的下载与切换
| 常用 | 操作 | 命令 | 说明 |
|---|---|---|---|
| ❗ | 【查】查看已有的环境 | conda env list |
列出所有已创建的环境 |
| ❗ | 【增】创建新环境 | conda create --name <env_name> python=<version> |
创建一个新环境,并指定 Python 版本 |
| ❗ | 【改】激活环境 | conda activate <env_name> |
激活指定的环境 |
| ❗ | 【改】退出当前环境 | conda deactivate |
退出当前激活的环境 |
| ❗ | 【删】删除环境 | conda remove --name <env_name> --all |
删除指定的环境 |
| ❗ | 【增】克隆环境 | conda create --name <new_env_name> --clone <old_env_name> |
克隆一个已有的环境 |
| 导出环境配置 | conda env export > environment.yml |
导出当前环境的配置到 .yml 文件 |
|
| 从文件导入环境 | conda env create -f environment.yml |
根据 .yml 文件创建环境 |
|
| 查看环境中的包 | conda list -n <env_name> |
查看指定环境中的所有包 | |
| 更新环境中的包 | conda update -n <env_name> <package> |
更新指定环境中的包 | |
| 删除环境中的包 | conda remove -n <env_name> <package> |
删除指定环境中的包 |
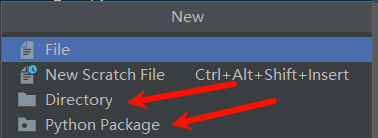
十二. 文件夹和包的区别
- & 源问题: python的Directory和Python Package有什么区别?
- & 视频: 1. init

十三. Python操作Redis
第一节 SET
| 方法名称 | 功能描述 | 示例代码 |
|---|---|---|
sadd |
向集合中添加一个或多个成员,若成员已存在则不重复添加 | python r.sadd('myset', 'apple', 'banana', 'cherry') |
scard |
获取集合中元素的数量 | python count = r.scard('myset') print(count) |
smembers |
获取集合中所有的成员 | python members = r.smembers('myset') print(members) |
sismember |
检查一个元素是否存在于集合中,存在返回1,不存在返回0 | python exists = r.sismember('myset', 'banana') print(exists) |
srandmember |
随机返回集合中的一个或多个成员,不删除该成员 | python random_member = r.srandmember('myset', number=2) print(random_member) |
spop |
随机移除并返回集合中的一个或多个成员 | python popped_member = r.spop('myset', count=1) print(popped_member) |
srem |
从集合中移除一个或多个成员 | python r.srem('myset', 'banana') |
smove |
将成员从一个集合移动到另一个集合,若成员不存在或目标集合不存在则返回0 | python moved = r.smove('myset', 'another_set', 'apple') print(moved) |
sinter |
计算多个集合的交集 | python r.sadd('set1', 'apple', 'orange') r.sadd('set2', 'banana', 'orange', 'grape') intersection_set = r.sinter('set1', 'set2') print(intersection_set) |
sunion |
计算多个集合的并集 | python union_set = r.sunion('set1', 'set2') print(union_set) |
sdiff |
计算多个集合的差集 | python difference_set = r.sdiff('set1', 'set2') print(difference_set) |
import redis
# 连接到 Redis 服务器
r = redis.Redis()
name = "test_redis_set"
# 【增】
r.sadd(name, '1', '2', '3', '4', '5')
print(r.smembers(name)) # set
# 【删】
aim_value = 2
r.srem(name, aim_value) # 删指定的value
print(r.smembers(name)) # set
# 【查】
print("随机获取一个: ", r.srandmember(name, 1)) # 返回<list>
print("检测是否有指的value", r.sismember(name, '2')) #有返回1,否则返回0
r.delete(name)
第X节 其他设置
13.X.1 如何设置自动解码
- & 说明: 默认从Redis中获取的数据, 都是字节数据, 但如果在获取连接的时候配置, 就会直接获取字符串数据而无需解码
- $ 语法:
decode_responses=True默认值(False), 默认获取解码后的String, 而不是二进制的String
r = redis.Redis(host='localhost', port=6379, db=0, decode_responses=True)
十四.发布到Pypi
发布后, 别人可以通过pip install来下载
第一节 如何上传
STEP1: 创建Pypi账号
- 官网: https://pypi.org/manage/projects/
- 关于API KEY: 必须开启”双因子验证”(用iPhone扫描QR)才能获取API KEY
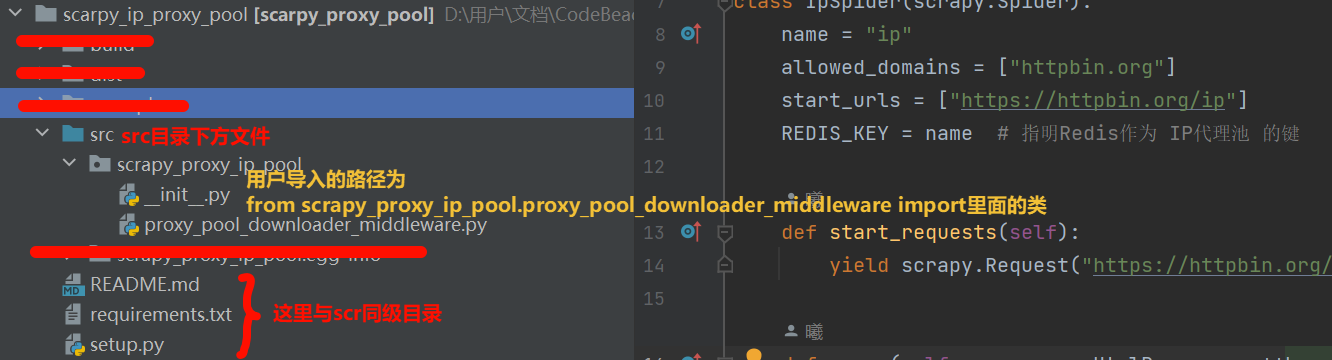
STEP2: 调整目录结构
setup.py必须要有, 每次发布的version不能相同, 发上去了就没办法了, 所以每次发布一定要确认清楚README.mdrequirements.txt可以没有
from setuptools import setup, find_packages
setup(
name='scrapy_proxy_ip_pool',
version='1.0.2',
packages=find_packages(where="src"),
package_dir={"": "src"},
install_requires=[
'Twisted>=20.3.0',
'zope.interface>=5',
'scrapy>=2.12.0',
'redis>=5.2.1',
'loguru>=0.7.2'
],
setup_requires=["setuptools>=42", "wheel"],
author='明廷盛',
author_email='1594365335@qq.com',
description='这是一个Scrapy中间件,用于管理代理IP池(支持使用Redis作为代理池)。',
long_description=open('README.md', encoding='utf-8').read(),
long_description_content_type='text/markdown',
url='https://github.com/Tlyer233/Scrapy-Proxy-IP-Pool',
classifiers=[
'Programming Language :: Python :: 3',
'Framework :: Scrapy',
],
entry_points={
'scrapy.middleware': [
'proxy_pool = scrapy_proxy_ip_pool.proxy_pool_downloader_middleware.ProxyPoolDownloaderMiddleware',
],
},
)
STEP3 发布
- $ 语法: 要先
pip install twine
python setup.py sdist bdist_wheel # 生成新的源码包和 Wheel 包
twine upload dist/* # 执行上传命令(会提示输入 API Token)
14.1.1 可能出现的问题
- 打包的时候死活报错==>miniconda专门建个环境
- 上传不上去把如下两个包删掉
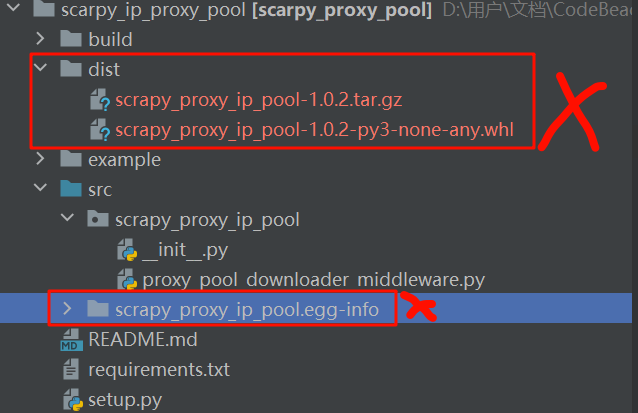
第二节 如何更新
STEP1: 修改setup.py:
- $ 语法: 把版本上升一个(同一版本不能发布两处)
STEP2: 删除以下目录结构
- 同14.1.1的删除内容
STEP3: 执行如下两条命令
- $ 语法: 和上传的一样
python setup.py sdist bdist_wheel
twine upload dist/*
pypi-AgEIcHlwaS5vcmcCJGRlNTZkMzE5LTEwNmUtNGFhZi1iOTI1LTFhNThiMGEwMjM1ZgACKlszLCJjNzlmNzEzMC03MmNiLTRkZjQtOTU5Ny1hN2ZlYTYzY2M4ZDEiXQAABiAZ7WnUQLzUlfIw028v-0cQdRkXEXC2euulztYEQjdUiw
STEP4: 下载新版本并使用
- 注意: 不要去镜像下, 因为官网是直接更新最新版本的, 其他下载源都有延迟!
pip install scrapy_proxy_ip_pool==1.0.1 -i https://pypi.org/simple
- Title: 2.需要用到的python基础知识
- Author: 明廷盛
- Created at : 2026-02-12 01:17:04
- Updated at : 2025-02-15 14:48:00
- Link: https://blog.20040424.xyz/2026/02/12/🐍爬虫工程师/第一部分 爬虫基础/2.需要用到的python基础知识/
- License: All Rights Reserved © 明廷盛